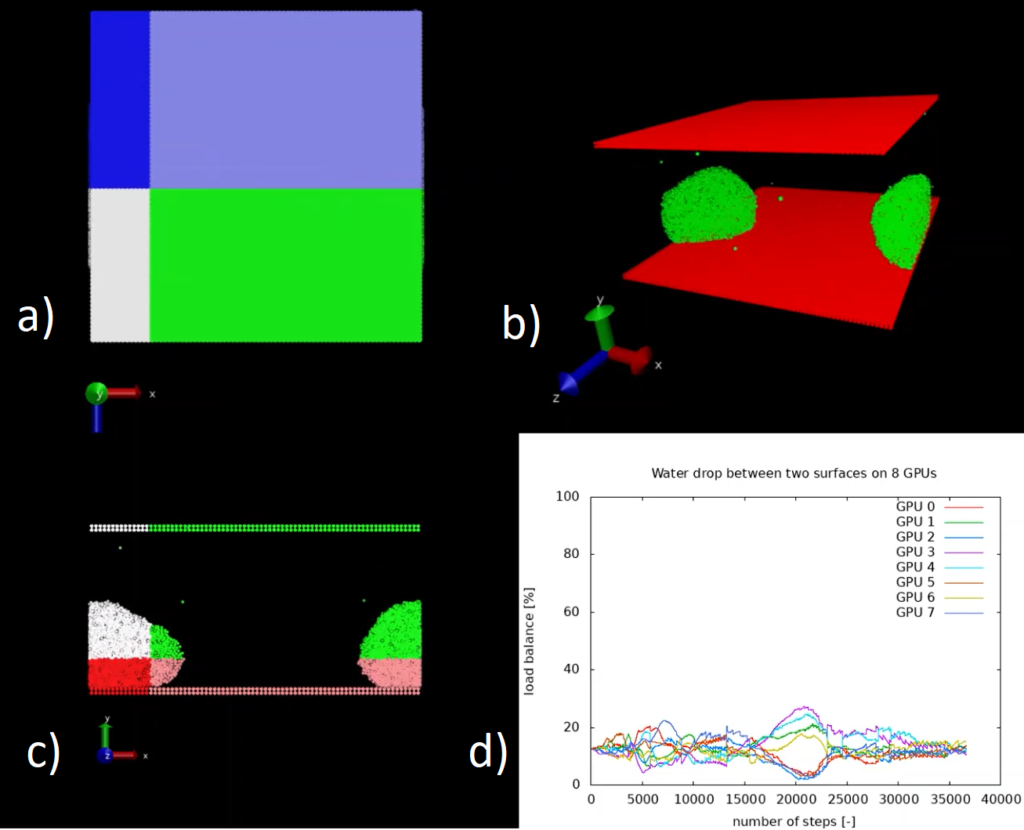
A test case was implemented (see Figure 1 a), b) and c)) that reproduces 32k water beads initially scattered along a regular structure and then slowly agglomerating towards an unique large drop confined between two parallel surfaces. The system is divided across 8 GPUs and, for the purposes of the visualisation, we restrict ourselves to 32k particles. For a larger number of particles it would not be possible to simulate the system without load-balancing, since all the particles agglomerate to a subset of the available GPUs and one or more GPUs would run out of memory having to accommodate a large number of particles. Moreover, such a strong load imbalance drastically reduces the scalability of the application.
In Figure d) we see the time history of the load imbalance for each GPU when using the ALL library. Without load balancing the system would gradually diverge from the ideal value of 12.5%. You can find a video that shows the evolution of the load-balancing for this system in another software module.
Figure 1: Load imbalance in DL_MESO with ALL library for a water drop between two surfaces. Each colour represents different domain assigned to a different GPU: a) top view, b) perspective view, c) front view, d) load balance vs time
Source code
Further details on the implementation of ALL library in DL_MESO and the source code can be found in the E-CAM software repository here.
In a newly successful PRACE-ICEI proposal, E-CAM, FocusCoE, HPC Carpentry and EESSI join forces to bring HPC resources to the classroom in a simple, secure and scalable way. Our plan is to reproduce the model developed by the Canadian open-source software project Magic Castle. The proposed solution creates virtual HPC infrastructure(s) in a public cloud, in this case on the Fenix Research Infrastructure, and generates temporary event-specific HPC clusters for training purposes, including a complete scientific software stack. The scientific software stack is fully optimised for the available hardware and will be provided by the European Environment for Scientific Software Installations (EESSI).
Description
EU-wide requirements for HPC training are exploding as the adoption of HPC in the wider scientific community gathers pace. However, the number of topics that can be thoroughly addressed without providing access to actual HPC resources is very limited, even at the introductory level. In cases where such access is available, security concerns and the overhead of the process of provisioning accounts make the scalability of this approach questionable.
EU-wide access to HPC resources on the scale required to meet the training needs of all countries is an objective that we attempt to address with this project. The proposed solution essentially provisions virtual HPC system(s) in a public cloud, in this case on the Fenix Research Infrastructure. The infrastructure will dynamically create temporary event-specific HPC clusters for training purposes, including a scientific software stack. The scientific software stack will be provided by the European Environment for Scientific Software Installations (EESSI) which uses a software distribution system developed at CERN, CernVM-FS, and makes a research-grade scalable software stack available for a wide set of HPC systems, as well as servers, desktops and laptops (including MacOS and Windows!).
The concept is built upon the solution of Compute Canada, Magic Castle, which aims to recreate the Compute Canada user experience in public clouds (there is even a presentation where the main developer creates a cluster just by talking to his phone!). Magic Castle uses the open-source software Terraform and HashiCorp Language (HCL) to define the virtual machines, volumes, and networks that are required to replicate a virtual HPC infrastructure.
In addition to providing a dynamically provisioned HPC resource, the project will also offer a scientific software stack provided by EESSI. This model is also based on a Compute Canada approach and enables replication of the EESSI software environment outside of any directly related physical infrastructure.
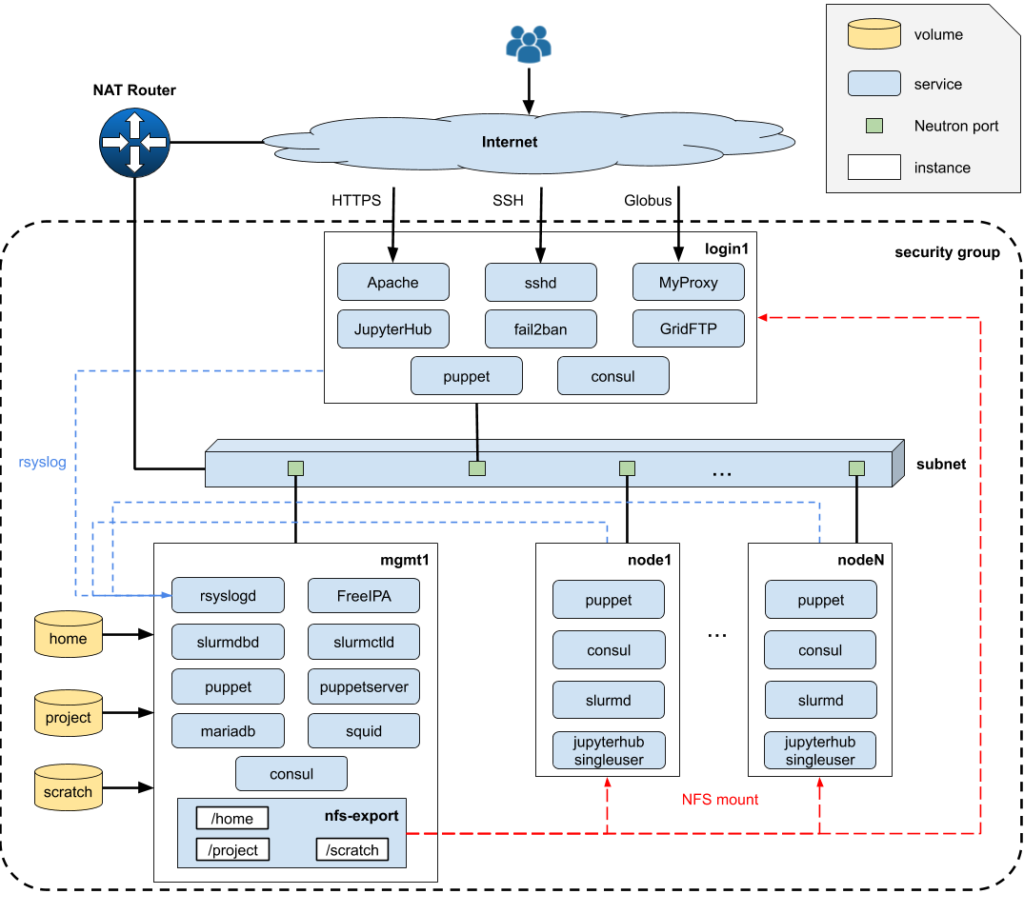
Our adaption of Magic Castle aims to recreate the EESSI HPC user experience, for training purposes, on the Fenix Research Infrastructure. After deployment, the user is provided with a complete HPC cluster software environment including a Slurm scheduler, a Globus Endpoint, JupyterHub, LDAP, DNS, and a wide selection of research software applications compiled by experts with EasyBuild.
With the resources made available to the project, we plan to run 6 HPC training events from January to July 2021. These training events are connected to the Centres of Excellence E-CAM and FocusCoE and with HPC Carpentry.
Few software, like DL_MESO, userMESO and LAMMPS, can currently simulate large Dissipative Particle Dynamics (DPD) simulations. In particular, DL_MESO [1, 2] has recently been ported to multi-GPU architectures and runs efficiently up to 4096 GPUs, an effort supported by E-CAM.
In this E-CAM Extended Software Development Workshop, the developers of the DL_MESO code themselves will provide an introduction to DPD, DL_MESO, its features and functionalities, as well as they will initiate participants to parallel programming of hybrid CPU-GPU systems. Part of the workshop will be dedicated to theory lectures and hands-on sessions on GPU architectures and OpenACC (NVidia DLI course) given by an NVidia DLI Certified Instructor, followed by the practical case of porting DL_MESO to OpenACC.
Interested in participating? Join us on the 18-22 January for this ONLINE course. Express your motivation to attend the workshop directly through the CECAM website at https://www.cecam.org/workshop-details/8
[2] M. A. Seaton, R. L. Anderson, S.Metz, and W. Smith, “DL_MESO: highly scalable mesoscale simulations,”Molecular Simulation, vol. 39, no. 10, pp. 796–821, Sep. 2013
Traditionally high-throughput computing (HTC) workloads are looked down upon in the HPC space, however the scientific use case for extreme-scale resources required by coordinated HTC workflows exists. For such cases where there may be thousands of tasks each requiring peta-scale computing, E-CAM has extended the data-analytics framework Dask with a capable and efficient library to handle such workloads.
Introduction
The initial motivation for E-CAM’s High Throughput Library, jobqueue_features library [1], is driven by the ensemble-type calculations that are required in many scientific fields, and in particular in the materials science domain. A concrete example is the study of molecular dynamics with atomistic detail, where timesteps must be used on the order of a femto-second. Many problems in biological chemistry and materials science involve events that only spontaneously occur after a millisecond or longer (for example, biomolecular conformational changes). That means that around 1012 time steps would be needed to see a single millisecond-scale event. This is the problem of “rare events” in theoretical and computational chemistry.
Modern supercomputers are beginning to make it possible to obtain trajectories long enough to observe some of these processes, but to fully characterize a transition with proper statistics, many examples are needed. In such cases the same peta-scale application must be run many thousands of times with varying inputs. For this use case, we were conceptually attracted to the Dask philosophy [2]: Dask is a specification that encodes task schedules with minimal incidental complexity using terms common to all Python projects, namely dicts, tuples, and callables.
However, Dask or it’s extensions do not currently support task-level parallelization (in particular multi-node tasks). We have been able to leverage the Dask extension dask_jobqueue [3] and build upon it’s functionality to include support for MPI-enabled task workloads on HPC systems. The resulting approach, described in the rest of this piece, allows for multi-level parallelization (at the task level via MPI, and at the framework level via Dask) while leveraging all of the pre-existing effort within the Dask framework such as scheduling, resilience, data management and resource scaling.
E-CAM’s HTC library was created in collaboration with a PRACE team in Wrocław, and is the subject of an associated white paper [4]. This effort is under continuous improvement and development. A series of dedicated webinars will happen in the fall of 2020, which will be an opportunity for people to learn how to use Dask and dask_jobqueue (to submit Dask workloads on a resource scheduler like SLURM), and to implement our library jobqueue_features in their codes. Announcement and more information will soon be available at https://www.e-cam2020.eu/calendar/.
Methodology
The jobqueue features library [1] is an extension of dask_jobqueue [3] which in turn utilizes the Dask [2] data analytics framework. dask_jobqueue is targeted at deploying Dask on several job queuing systems, such as SLURM or PBS with the use of a Python programming interface. The main enhancements of basic dask_jobqueue functionality is heavily extending the configuration implementation to handle MPI runtimes and different resource specifications. This allows the end-user to conveniently create parallelized tasks without extensive knowledge of the implementation details (e.g., the resource manager or MPI runtime). The library is primarily accessed through a set of Python decorators: on_cluster, task and mpi_task. The on_cluster decorator gets or creates clusters, which in turn submit worker resource allocation requests to the scheduler to execute tasks. The mpi_task decorator derives from task and enhances it with MPI specific settings (e.g. the MPI runtime and related settings).
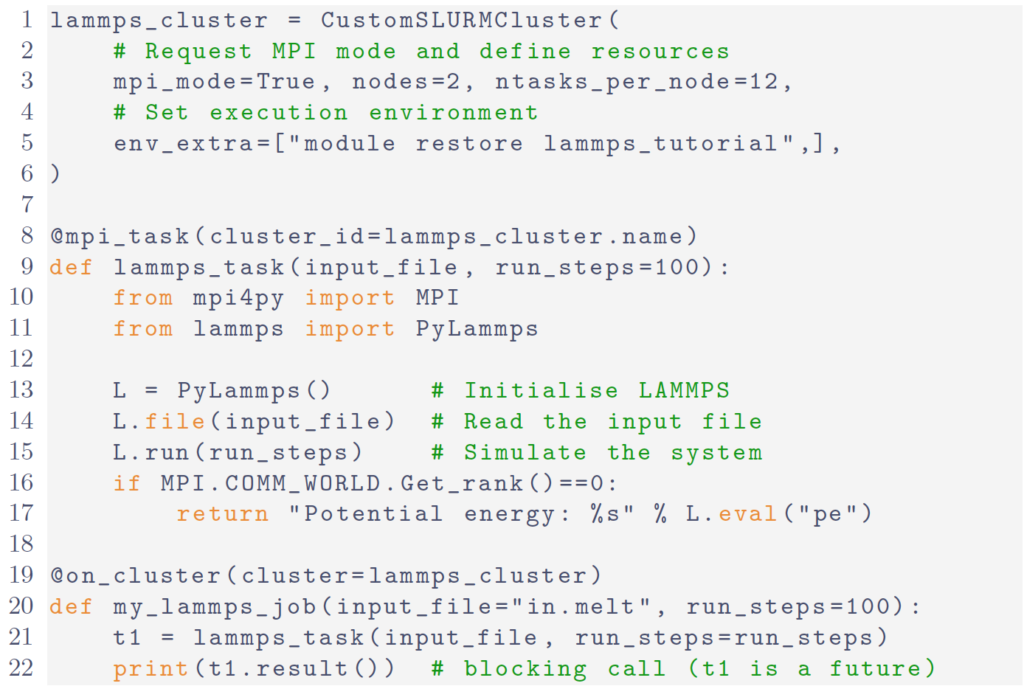
Fig. 1: Example of decorator usage to parallelize computation
In Fig. 1 we show a minimal, but complete, example which uses the mpi_task and on_cluster decorators for a LAMMPS execution. The configuration, communication and serialization is isolated and hidden from user code.
Any call to my_lammps_job results in the lammps_task function being executed remotely by a lammps_cluster worker allocated by the resource manager with 2 nodes and 12 MPI tasks per node. The code can be executed interactively in a Jupyter notebook. To overlap calculations one would need to return the t1 future rather than the actual result.
Findings
The library can effectively handle simultaneous workloads on GPU, KNL and CPU partitions of the JURECA supercomputer [5]. The caveat with respect to the hardware environment is that you need to be able to have a network that supports TCP (usually via IPoIB) or UCX connections between the scheduler and the workers (which process and execute the tasks that are queued).
With respect to the software stack, this is an issue highlighted by the KNL booster of JURECA. On the booster, there is a different micro-architecture and it is required to completely change your software stack to support this. The design of the software stack implementation on JURECA simplifies this but ensuring your tasks are run in the correct software environment is one of the more difficult things to get right in the library. As a result, the configuration of the clusters (which define the template required to submit workers to the appropriate queue of the resource manager) can be quite non-trivial. However, they can be located within a single file which will need to be tuned for the available resources. With respect to the tasks themselves, no tuning is necessarily required.
We see ∼90% throughput efficiency for trivial tasks, if the tasks executed for any reasonable length of time this throughout efficiency would be much higher.
Conclusions
The library is flexible, scalable, efficient and adaptive. It is capable of simultaneously utilising CPUs, KNL and GPUs (or any other hardware) and dynamically adjusting its use of these resources based on the resource requirements of the scheduled task workload. The ultimate scalability and hardware capabilities of the solution is dictated by the characteristics of the tasks themselves with respect to these. For example, for the use case described here these would mean the hardware and scalability capabilities of LAMMMPS with a further multiplicative factor coming from the library for the number of tasks running simultaneously. There is, unsurprisingly, room for further improvement and development, in particular related to error handling and limitations related to the Python GIL.
[4] A. O. Cais, D. Swenson, M. Uchronski and A. Wlodarczyk. (2019, Augoust 14). “Task Scheduling Library for Optimising Time-Scale Molecular Dynamics Simulations,” Zenodo. http://doi.org/10.5281/zenodo.3527643
In a recent paper[1], researchers from the Centres of Excellence E-CAM[2] and MaX[3], and the centre for Computational Design and Discovery of Novel Materials NCCR MARVEL[4], have proposed a new procedure for automatically generating Maximally-Localised Wannier functions (MLWFs) for high-throughput frameworks. The methodology and associated software can be used for hitherto difficult cases of entangled bands, and allows the electronic properties of a wide variety of materials to be obtained starting only from the specification of the initial crystal structure, including insulators, semiconductors and metals. Industrial applications that this work will facilitate include the development of novel superconductors, multiferroics, topological insulators, as well as more traditional electronic applications.
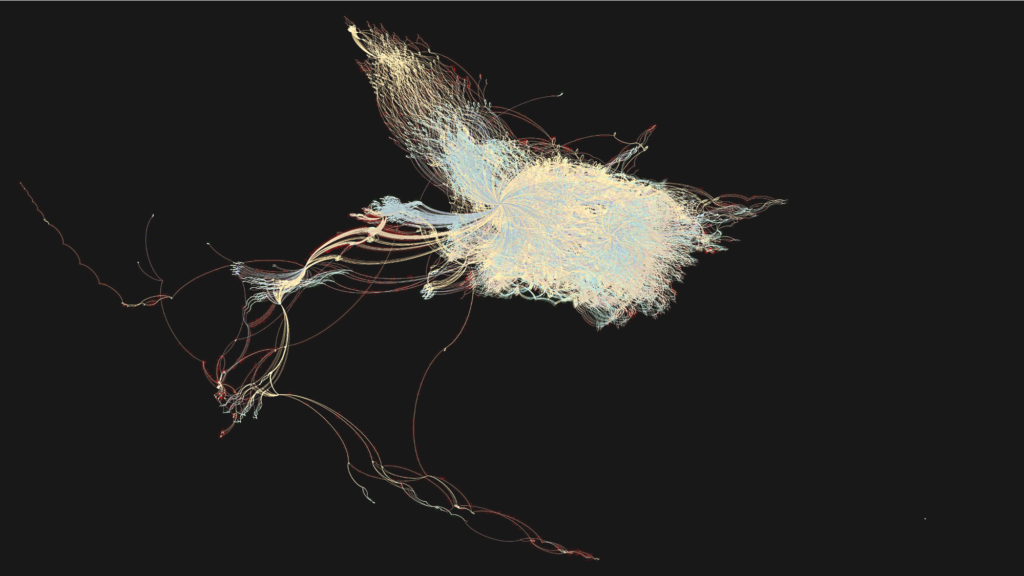
Graphical representation of all data and calculations run in the project and their interconnections (provenance), as tracked automatically by AiiDA in the form of a directed acyclic graph (image credits: G. Pizzi)
Challenge/context
Predicting the properties of complex materials generally entails the use of methods that facilitate coarse grained perspectives more suitable for large scale modelling, and ultimately device design and manufacture. When a quantum level of description of a modular-like system is required, this can often be facilitated by expressing the Hamiltonian in terms of a localised, real-space basis set, enabling it to be partitioned without ambiguity into sub-matrices that correspond to the individual subsystems. Maximally-localised Wannier functions (MLWFs) are particularly suitable in this context. However, until now generating MLWFs has been difficult to exploit in high-throughput design of materials, without the specification by users of a set of initial guesses for the MLWFs, typically trial functions localised in real space, based on their experience and chemical intuition.
Solution
E-CAM[2] scientist Valerio Vitale and co-authors from the partner H2020 Centre of Excellence MAX[3] and the Swiss based NCCR MARVEL [4] in a recent article[1] look afresh at this problem in the context of an algorithm by Damle et al[5], known as the selected columns of the density matrix (SCDM) method, as a method to provide automatically initial guesses for the MLWF search, to compute a set of localized orbitals associated with the Kohn–Sham subspace for insulating systems. This has shown great promise in avoiding the need for user intervention in obtaining MLWFs and is robust, being based on standard linear-algebra routines rather than on iterative minimisation. In particular, Vitale et al. developed a fully-automated protocol based on the SCDM algorithm in which the three remaining free parameters (two from the SCDM method, plus the choice of the target dimensionality for the disentangled subspace) are determined automatically, making it thus parameter-free even in the case of entangled bands. The work systematically compares the accuracy and ease of use of standard methods to generate localised basis sets as (a) MLWFs; (b) MLWFs combined with SCDM’s and (c) using solely SCDM’s; and applies this multifaceted perspective to hundreds of materials including insulators, semiconductors and metals.
Comparison between Wannier-interpolated valence bands (red lines) and the full direct-DFT band structure (black lines), for 150 different materials. The direct and interpolated band structures are essentially indistinguishable (image credits: G. Pizzi)
Benefit
This is significant because it greatly expands the scope of materials for which MLWFs can be generated in high throughput studies and has the potential to accelerate the design and discovery of materials with tailored properties using first-principles high-throughput (HT) calculations, and facilitate advanced industrial applications. Industrial applications that this work will facilitate include the development of novel superconductors, multiferroics, topological insulators, as well as more traditional electronic applications.
Background information
This module is a collaboration between the E-CAM and MaX HPC centres of excellence, and the NCCR MARVEL.
In SCDM Wannier Functions, E-CAM has implemented the SCDM algorithm in the pw2wannier90 interface code between the Quantum ESPRESSO software and the Wannier90 code. This was done in the context of an E-CAM pilot project at the University of Cambridge. Researchers have then used this implementation as the basis for a complete computational workflow for obtaining MLWFs and electronic properties based on Wannier interpolation of the Brillouin zone, starting only from the specification of the initial crystal structure. The workflow was implemented within the AiiDA materials informatics platform (from the NCCR MARVEL and the MaX CoE) , and used to perform a HT study on a dataset of 200 materials.
Source Code
See the Materials Cloud Archive entry. A downloadable virtual machine is provided that allows to reproduce the results of the associated paper and also to run new calculations for different materials, including all first-principles and atomistic simulations and the computational workflows.
Bibliography
[1] Automated high-throughput Wannierisation, Valerio Vitale, Giovanni Pizzi, Antimo Marrazzo, Jonathan R. Yates, Nicola Marzari and Arash A. Mostofi, Nature Computational Materials (2020)6:66 ; https://doi.org/10.1038/s41524-020-0312-y
[5] Compressed Representation of Kohn−Sham Orbitals via Selected Columns of the Density Matrix , Anil Damle, Lin Lin, and Lexing Ying, J. Chem. Theory Comput. 2015, 11, 1463−1469 https://pubs.acs.org/doi/10.1021/ct500985f
The new CECAM webinar series entitled “The importance of being H.P.C. Earnest”, will focus on of HPC as an enabler of leading-edge simulation and modelling, and on the science made possible by combining state-of-the-art methods with optimal exploitation of supercomputing resources.
A series of 5 CECAM webinars will be held every Thursday 15:00-17:00 (CEST) and broadcasted live on the CECAM YouTube Channel, starting on June 18 2020.
Different experts, who are also key players in projects targeting software development for high-end computational facilities, such as the European Centers of Excellence for Computing Applications and analogous initiatives based in the United States of America, will be present for this occasion.
The E-CAM Centre of Excellence will be featured on Thursday 2 July 2020 by Prof. Ignacio Pagonabarraga, CECAM Director and Technical Manager of E-CAM.
The full programme for the webinar series is the following:
Chapter 1: Thursday, 18 June 2020
Nicola Marzari – EPFL Claudia Filippi – University of Twente Anthony Scemama – University of Toulouse III Giulia Galli – University Of Chicago And Argonne National Laboratory
Chapter 2 : Thursday, 25 June 2020
Erik Lindahl – Stockholm University Jesus Labarta – Barcelona Supercomputing Center Paul Kent – Oak Ridge National Laboratory
Chapter 3 : Thursday, 2 July 2020
Cecilia Clementi – Freie Universität Berlin Ignacio Pagonabarraga – CECAM Peter Coveney – University College London and University of Amsterdam
Chapter 4 : Thursday, 9 July 2020
Edouard Audit – CEA Elisa Molinari – University of Modena Gianluca Palermo – Politecnico di Milano
Chapter 5: Thursday 16 July 2020
Steven G. Louie – University of Berkeley Claudia Draxl – Humboldt University Berlin
HPC facilities are a major capital investment and often run close to capacity. Improving the efficiency of application software running on these facilities either speeds up time to solution or allows for larger, more challenging problems to be solved. The Performance Optimisation and Productivity (POP) Centre of Excellence exists to help academic and industry groups identify how their software can be improved, free of charge. Funded by the EU under the Horizon 2020 Research and Innovation Programme, POP puts the world-class HPC expertise of eight commercial and academic partners at the disposal of European Scientists and Industry.
Collaborations with the POP CoE
Given that POP is home to a large set of performance experts, E-CAM has collaborated with them on (to date) two applications that are of particular interest to E-CAM with respect to extreme scalability: ESPResSo++ and PaPIM. We have also benefitted from their HPC specialists in one of our Extended Software Development Workshops organized by the Electronic Structure Library initiative[1] (ESL), where POP’s experts provided a 1.5 day Tutorial on advanced performance and scalability profiling of the ESL libraries.
Successful collaboration with POP: Optimization of PaPIM
POP carried out a study of PaPIM[2] which resulted in a 10 page report on its performance, highlighting issues in the code and proposing remedies. For example, the report showed that load imbalance issues in the expensive part of the application was mainly related to an uneven spread of the sample groups among the MPI tasks. Of more interest was the communication pattern, where the POP analysis showed that replacing a number of successive collective communications with a single collective of a derived data type could lead to a 4.7 x improvement in communication performance.
How it works
A simple request form should be completed at https://pop-coe.eu/request-service-form. One of their technical experts will be in touch to obtain the details.
Briefly, POP services involve the following steps.
The first step is to profile the application behaviour using suitable parallel profiling tools, e.g. Extrae or Scalasca. This step creates trace files which require analysis by POP experts. This is typically done on the user’s machines. However, if this is not an option for a user, POP can collect performance data on one of their HPC machines. This task can be done either by POP experts or by users with POP support.
The results from the analysis of the trace files are presented to the user, explaining the performance issues with the code and recommendations for performance improvements. Experience shows that it is often difficult to build a quantitative picture of parallel application behaviour. One of the strengths of POP is their set of metrics, which provide a standard, objective way to characterise different aspects of the performance of parallel codes.
POP performance assessment can be followed up by further work, again completely free to the user, to demonstrate how to implement these improvements.
A feature that is particularly useful when dealing with industrial partnerships, is that POP services don’t require access to the source code – they can work with executables. And if needed, non-disclosure agreements can be signed.
[2] PaPIM is a code for computing time-dependent correlation functions and sampling of the phase space. It samples the phase space either classically or quantum mechanically. Documentation available here.
This module is the first in a sequence that will form the overall capabilities of the E-CAM High Throughout Computing (HTC) library. In particular this module deals with creating a set of decorators to wrap around the Dask-Jobqueue Python library, which aspires to make the development time cost of leveraging it lower for our use cases.
The initial motivation for this library is driven by the ensemble-type calculations that are required in many scientific fields, and in particular in the materials science domain in which the E-CAM Centre of Excellence operates.
One specific application for this module is the study of “rare events” in theoretical and computational chemistry, a particularly relevant topic for E-CAM . Many problems in biological chemistry, materials science, and other fields involve events that only spontaneously occur after a millisecond or longer (for example, biomolecular conformational changes, or nucleation processes). That means that around 1012 time steps would be needed to see a single millisecond-scale event.
Modern supercomputers are beginning to make it possible to obtain trajectories long enough to observe some of these processes, but to fully characterize a transition with proper statistics, many examples are needed. In order to obtain many examples the same application must be run many thousands of times with varying inputs. To manage this kind of computation a task scheduling high throughput computing (HTC) library is needed. The main elements of the mentioned scheduling library are: task definition, task scheduling and task execution.
While traditionally an HTC workload is looked down upon in the HPC space, the scientific use case for extreme-scale resources exists and algorithms that require a coordinated approach make efficient libraries that implement this approach increasingly important in the HPC space. The 5 Petaflop booster technology of JURECA is an interesting concept with respect to this approach since the offloading approach of heavy computation marries perfectly to the concept outlined here.
E-CAM researchers working at the Hartree Centre – Daresbury Laboratory have co-designed the DL_MESO Mesoscale Simulation package to run on multiple GPUs, and ran for the first time a Dissipative Particle Dynamics simulation of a very large system (1.8 billion particles) on 4096 GPUs.
Towards extreme scale dissipative particle dynamics simulations using multiple GPGPUs J. Castagna, X. Guo, M. Seaton and A. O’Cais Computer Physics Communications (2020) 107159 DOI: 10.1016/j.cpc.2020.107159 (open access)
Abstract
A multi-GPGPU development for Mesoscale Simulations using the Dissipative Particle Dynamics method is presented. This distributed GPU acceleration development is an extension of the DL_MESO package to MPI+CUDA in order to exploit the computational power of the latest NVIDIA cards on hybrid CPU–GPU architectures. Details about the extensively applicable algorithm implementation and memory coalescing data structures are presented. The key algorithms’ optimizations for the nearest-neighbour list searching of particle pairs for short range forces, exchange of data and overlapping between computation and communications are also given. We have have carried out strong and weak scaling performance analyses with up to 4096 GPUs. A two phase mixture separation test case with 1.8 billion particles has been run on the Piz Daint supercomputer from the Swiss National Supercomputer Center. With CUDA aware MPI, proper GPU affinity, communication and computation overlap optimizations for multi-GPU version, the final optimization results demonstrated more than 94% efficiency for weak scaling and more than 80% efficiency for strong scaling. As far as we know, this is the first report in the literature of DPD simulations being run on this large number of GPUs. The remaining challenges and future work are also discussed at the end of the paper.