
Abstract
Traditionally high-throughput computing (HTC) workloads are looked down upon in the HPC space, however the scientific use case for extreme-scale resources required by coordinated HTC workflows exists. For such cases where there may be thousands of tasks each requiring peta-scale computing, E-CAM has extended the data-analytics framework Dask with a capable and efficient library to handle such workloads.
Introduction
The initial motivation for E-CAM’s High Throughput Library, jobqueue_features library [1], is driven by the ensemble-type calculations that are required in many scientific fields, and in particular in the materials science domain. A concrete example is the study of molecular dynamics with atomistic detail, where timesteps must be used on the order of a femto-second. Many problems in biological chemistry and materials science involve events that only spontaneously occur after a millisecond or longer (for example, biomolecular conformational changes). That means that around 1012 time steps would be needed to see a single millisecond-scale event. This is the problem of “rare events” in theoretical and computational chemistry.
Modern supercomputers are beginning to make it possible to obtain trajectories long enough to observe some of these processes, but to fully characterize a transition with proper statistics, many examples are needed. In such cases the same peta-scale application must be run many thousands of times with varying inputs. For this use case, we were conceptually attracted to the Dask philosophy [2]: Dask is a specification that encodes task schedules with minimal incidental complexity using terms common to all Python projects, namely dicts, tuples, and callables.
However, Dask or it’s extensions do not currently support task-level parallelization (in particular multi-node tasks). We have been able to leverage the Dask extension dask_jobqueue [3] and build upon it’s functionality to include support for MPI-enabled task workloads on HPC systems. The resulting approach, described in the rest of this piece, allows for multi-level parallelization (at the task level via MPI, and at the framework level via Dask) while leveraging all of the pre-existing effort within the Dask framework such as scheduling, resilience, data management and resource scaling.
E-CAM’s HTC library was created in collaboration with a PRACE team in Wrocław, and is the subject of an associated white paper [4]. This effort is under continuous improvement and development. A series of dedicated webinars will happen in the fall of 2020, which will be an opportunity for people to learn how to use Dask and dask_jobqueue (to submit Dask workloads on a resource scheduler like SLURM), and to implement our library jobqueue_features in their codes. Announcement and more information will soon be available at https://www.e-cam2020.eu/calendar/.
Methodology
The jobqueue features library [1] is an extension of dask_jobqueue [3] which in turn utilizes the Dask [2] data analytics framework. dask_jobqueue is targeted at deploying Dask on several job queuing systems, such as SLURM or PBS with the use of a Python programming interface. The main enhancements of basic dask_jobqueue functionality is heavily extending the configuration implementation to handle MPI runtimes and different resource specifications. This allows the end-user to conveniently create parallelized tasks without extensive knowledge of the implementation details (e.g., the resource manager or MPI runtime). The library is primarily accessed through a set of Python decorators: on_cluster, task and mpi_task. The on_cluster decorator gets or creates clusters, which in turn submit worker resource allocation requests to the scheduler to execute tasks. The mpi_task decorator derives from task and enhances it with MPI specific settings (e.g. the MPI runtime and related settings).
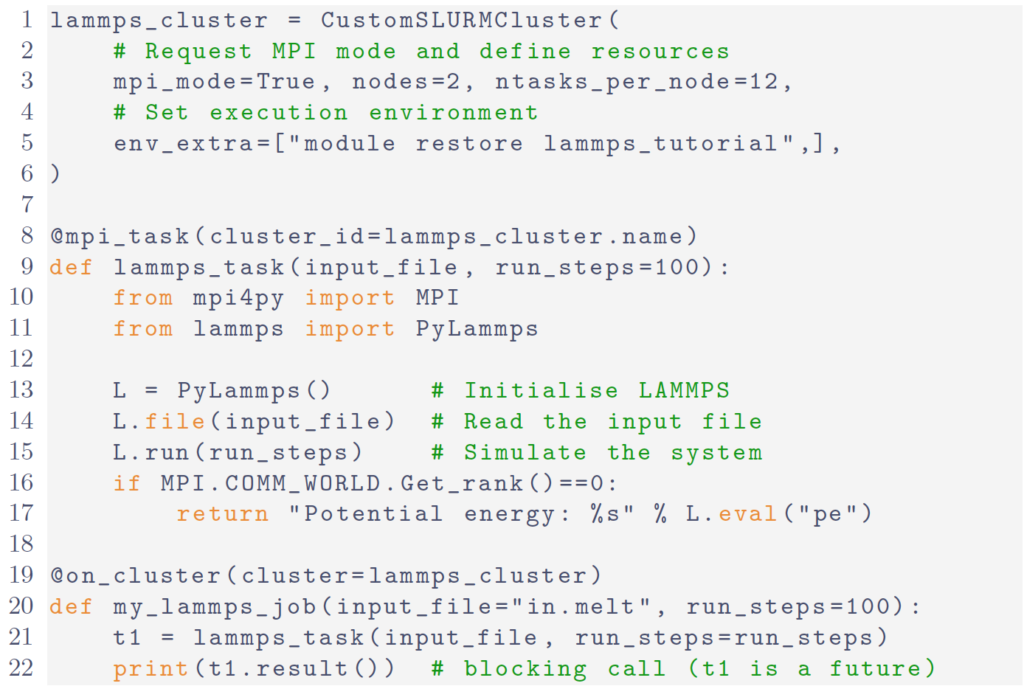
In Fig. 1 we show a minimal, but complete, example which uses the mpi_task and on_cluster decorators for a LAMMPS execution. The configuration, communication and serialization is isolated and hidden from user code.
Any call to my_lammps_job results in the lammps_task function being executed remotely by a lammps_cluster worker allocated by the resource manager with 2 nodes and 12 MPI tasks per node. The code can be executed interactively in a Jupyter notebook. To overlap calculations one would need to return the t1 future rather than the actual result.
Findings
The library can effectively handle simultaneous workloads on GPU, KNL and CPU partitions of the JURECA supercomputer [5]. The caveat with respect to the hardware environment is that you need to be able to have a network that supports TCP (usually via IPoIB) or UCX connections between the scheduler and the workers (which process and execute the tasks that are queued).
With respect to the software stack, this is an issue highlighted by the KNL booster of JURECA. On the booster, there is a different micro-architecture and it is required to completely change your software stack to support this. The design of the software stack implementation on JURECA simplifies this but ensuring your tasks are run in the correct software environment is one of the more difficult things to get right in the library. As a result, the configuration of the clusters (which define the template required to submit workers to the appropriate queue of the resource manager) can be quite non-trivial. However, they can be located within a single file which will need to be tuned for the available resources. With respect to the tasks themselves, no tuning is necessarily required.
We see ∼90% throughput efficiency for trivial tasks, if the tasks executed for any reasonable length of time this throughout efficiency would be much higher.
Conclusions
The library is flexible, scalable, efficient and adaptive. It is capable of simultaneously utilising CPUs, KNL and GPUs (or any other hardware) and dynamically adjusting its use of these resources based on the resource requirements of the scheduled task workload. The ultimate scalability and hardware capabilities of the solution is dictated by the characteristics of the tasks themselves with respect to these. For example, for the use case described here these would mean the hardware and scalability capabilities of LAMMMPS with a further multiplicative factor coming from the library for the number of tasks running simultaneously. There is, unsurprisingly, room for further improvement and development, in particular related to error handling and limitations related to the Python GIL.
References
[1] jobqueue features repository, https://github.com/E-CAM/jobqueue_features
[2] Dask documentation, https://dask.org.
[3] Dask-Jobqueue documentation, https://jobqueue.dask.org/.
[4] A. O. Cais, D. Swenson, M. Uchronski and A. Wlodarczyk. (2019, Augoust 14). “Task Scheduling Library for Optimising Time-Scale Molecular Dynamics Simulations,” Zenodo. http://doi.org/10.5281/zenodo.3527643
[5] Krause, D. and Thörnig, P.: JURECA: Modular supercomputer at Jülich Supercomputing Centre, http://juser.fz-juelich.de/record/850758 (2016)
