
Description
This module concerns the implementation of the E-CAM Load Balancing Library (ALL) in the multi-GPU version of DL_MESO_DPD code. The intention is to allow for better performance when modelling complex systems with DL_MESO_DPD, like large proteins or lipid bilayers, redistributing the work load across the GPUs.
ALL provides several schemes to find the ideal split of the work load : Tensor-Product method, Staggered Grid Method, Unstructured Mesh Method, Voronoi Mesh Method and Histogram-based Staggered Grid Method. Due to the orthogonal domain decomposition used in DL_MESO, the Tensor-Product scheme was used, which works well for non-staggered orthogonal meshes.
Practical application
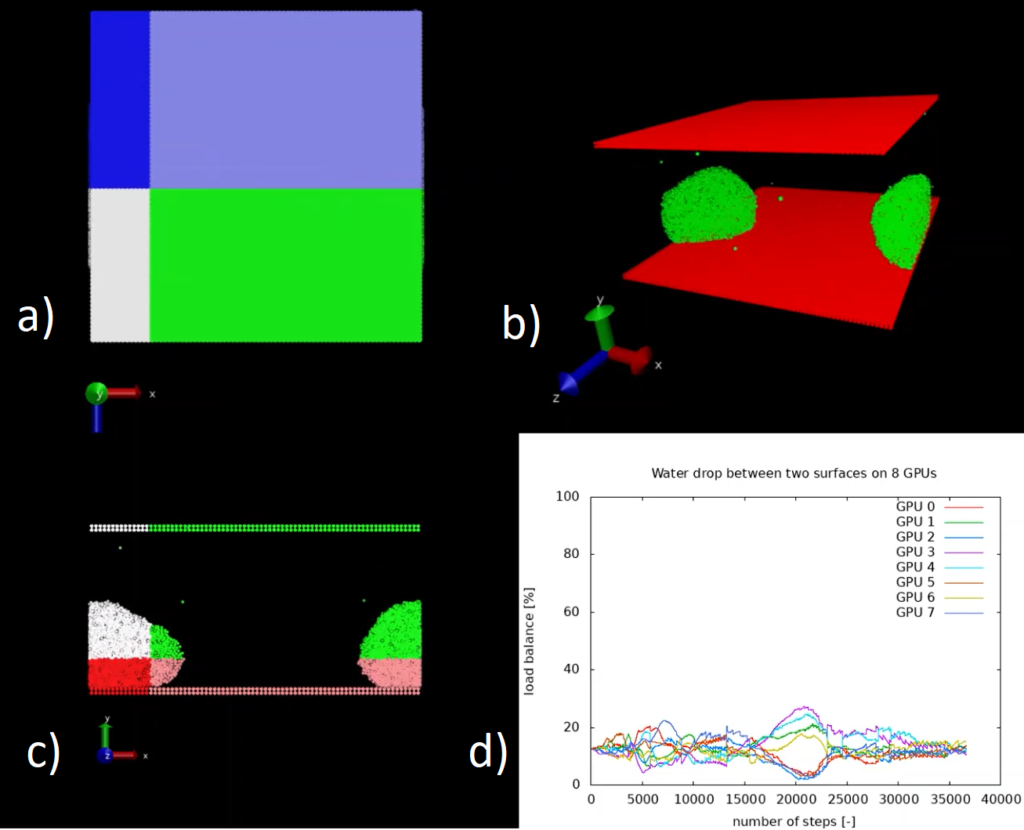
A test case was implemented (see Figure 1 a), b) and c)) that reproduces 32k water beads initially scattered along a regular structure and then slowly agglomerating towards an unique large drop confined between two parallel surfaces. The system is divided across 8 GPUs and, for the purposes of the visualisation, we restrict ourselves to 32k particles. For a larger number of particles it would not be possible to simulate the system without load-balancing, since all the particles agglomerate to a subset of the available GPUs and one or more GPUs would run out of memory having to accommodate a large number of particles. Moreover, such a strong load imbalance drastically reduces the scalability of the application.
In Figure d) we see the time history of the load imbalance for each GPU when using the ALL library. Without load balancing the system would gradually diverge from the ideal value of 12.5%. You can find a video that shows the evolution of the load-balancing for this system in another software module.
Source code
Further details on the implementation of ALL library in DL_MESO and the source code can be found in the E-CAM software repository here.
