This module describes the work done in E-CAM in cooperation with the HemeLB code from the CompBioMed Centre of Excellence.
HemeLB is a high performance lattice-Boltzmann solver optimised for simulating blood flow through sparse geometries, such as those found in the human vasculature. The code is used within the CompBioMed HPC Centre of Excellence H2020 project and is already highly optimised for HPC usage. Nevertheless, in an E-CAM workshop on the load balancing library ALL hosted at the Juelich Supercomputing Centre, a cooperation was set up in order to analyse and test whether the use of ALL could improve the existing scalability of the code.
ALL was designed to work with particle codes, therefore it was interesting to apply the library to a lattice-Boltzmann solver, which usually is not particle-based. The different grid points of the solution grid were designated as particles and since each of the grid-points already was assigned a workload, the sum of grid-point workloads could be used as domain work load.
As a result, it was demonstrated that the domain compositions provided by ALL show a better theoretical load distribution. Tests to check if this translates into better code performance are inconclusive as yet, due to hardware related issues on the testing platforms. However, these are currently under further investigation, and more definitive results about the performance of the ALL-provided domain decompositions can be expected in the near future. The results were part of an article about HemeLB, which was published in 2020[1] .
Towards blood flow in the virtual human: efficient self-coupling of HemeLB J. W. S. McCullough, R. A. Richardson, A. Patronis, R. Halver, R. Marshall, M. Ruefenacht, B. J. N. Wylie, T. Odaker, M. Wiedemann, B. Lloyd, E. Neufeld, G. Sutmann, A. Skjellum, D. Kranzlmüller and P. V. Coveney Interface Focus2020, 11: 20190119 DOI: http://dx.doi.org/10.1098/rsfs.2019.0119 (open access)
To further expand the portfolio of activities targeted at industrialists, E-CAM has established a series of new events targeted at training interested industrial researchers on the simulation and modelling techniques implemented in specific codes and in the direct use of this software for their industrial applications.
The first event of this series will focus on the area of meso- and multiscale simulations and on the flagship code DL_MESO:
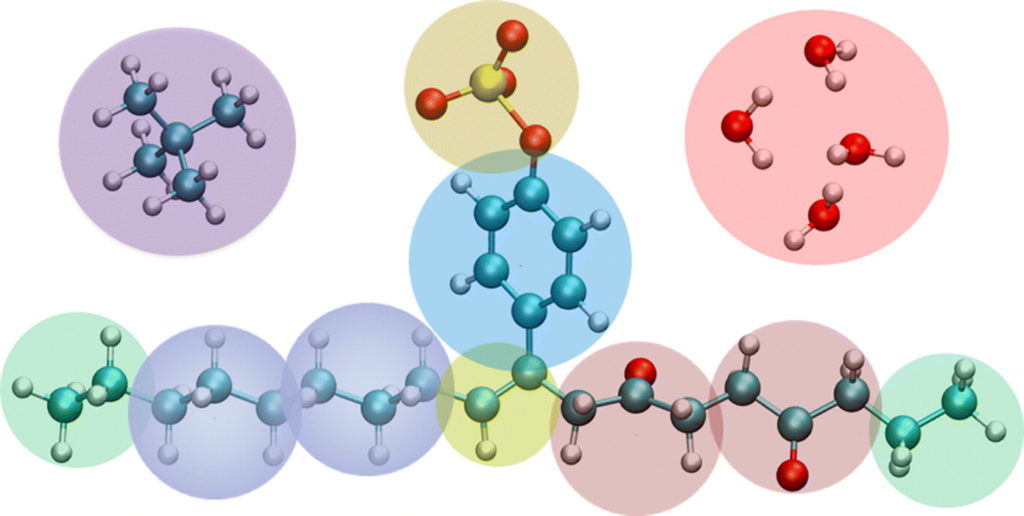
In this workshop we will introduce DL_MESO: a software package for mesoscale simulations. Usage of the software will be gradually presented, starting with tutorials based on theoretical background and following up with hands-on sessions. We will focus on the Dissipative Particle Dynamics (DPD) methodology, exploring the different capabilities of DL_MESO_DPD via practical examples that reflect daily industrial challenges.
DL_MESO has been used for a wide range of problems of both scientific and industrial interest. The code is used, for example, in projects with Unilever, Syngenta and Infineum – to develop DPD parameterisation strategies and simulation protocols to predict important properties of newly-devised surfactant-based formulations; with IBM Research Europe – to model nanofluidic multiphase. The code developers themselves will provide the training. The event is co-organized by Formeric, a company that helps industrial users to study their own formulated projects, primarily by developing a software platform to make it easier for them to access DPD simulations and modelling tools.
As part of the event, UKRI STFC offers a 6-month one seat free licence of DL_MESO 2.7 to be used soon after the end of the event, which will help testing the software.
Don’t miss this opportunity to be trained by the experts on the methods and on the codes themselves! Register for event at
Our last Extended Software Development Workshop (ESDW) took place on the 18th-22nd January[1], and given its length (5 days) and it’s nature (theory and hands-on training sessions) it was a real success! “The workshop went very well, participants seem to have enjoyed and they lasted until the end !”, said organiser Jony Castagna, computational scientist and E-CAM programmer at UKRI STFC Daresbury Laboratory. The event, organised at the CECAM-UK-DARESBURY Node[2], focused on HPC for mesoscale simulation, and aimed at introducing participants to Dissipative Particle Dynamics (DPD) and the mesoscale simulation package DL_MESO [3] (DL_MESO_DPD). DL_MESO is developed at UKRI STFC Daresbury by Michael Seaton, computational chemist at Daresbury and also an organiser of this event.
Another component of this workshop was parallel programming of hybrid CPU-GPU systems. In particular, DL_MESO has recently been ported to multi-GPU architectures[4] and runs efficiently up to 4096 GPUs, an effort supported by E-CAM (thank you Jony!). Part of this workshop was dedicated to theory lectures and hands-on sessions on GPU architectures and OpenACC (NVidia DLI course) given by Jony, which is an NVidia DLI Certified Instructor. He said “The intention is not only to port mesoscale solvers on GPUs, but also to expose the community to this new programming paradigm, which they can benefit from in their own fields of research”.
All sessions in this ESDW were followed by discussions and hands-on exercises. Organisers were supported by another STFC colleague and former E-CAM post-doc Silvia Chiacchiera. One of the participants wrote “Thank you so much for your effort. This workshop will cause a significant shift in my thinking and approach”.
21 people registered for to the event; but by the third day there were only 9… from which 5 lasted until the last session! A picture taken from the last session talks by itself 🙂
Do you want to join our next training event ? Check out our programme :
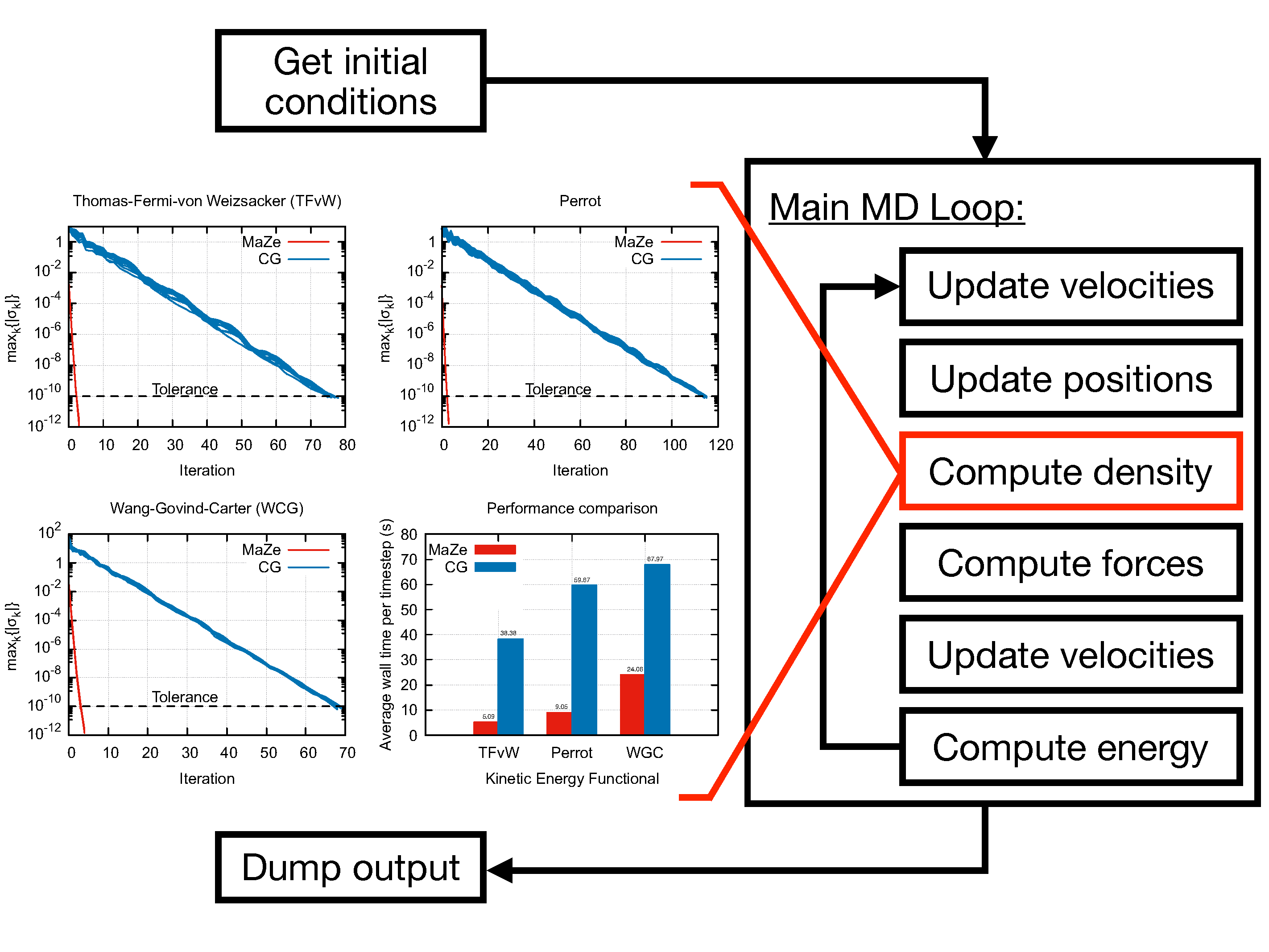
The program performs Orbital-Free Density Functional Theory Molecular Dynamics (OF-DFT-MD) using the Mass-Zero (MaZe) constrained molecular dynamics approach described in [1].
This method enforces, at each time step, the Born-Oppenheimer condition that the system relaxes instantaneously to the ground state through the formalism of massless constraints. The adiabatic separation between the degrees of freedom is enforced rigorously, and the algorithm is symplectic and time-reversible in both physical and additional set of degrees of freedom.
The computation of the electronic density is carried out in reciprocal space through a plane-waves expansion so that the mass-zero degrees of freedom are associated to the Fourier coefficients of the electronic density field. The evolution of the ions is performed using Velocity-Verlet algorithm, while the SHAKE algorithm is used for computation of the additional degrees of freedom. The code can sample the NVE and the NVT ensemble, the latter through a Langevin thermostat.
The code was optimised to run on HPC machines, as explained in the software documentation. The proposed optimisations allow a reduction of the execution time by roughly 50% compared to the original version of the code.
Caption: MaZe optimisation of the electronic density at each nuclear step along an orbital-free DFT Born–Oppenheimer trajectory. Very high speed of convergence is achieved by interpreting the optimisation as a constraint solved via an original implementation of the SHAKE algorithm. The number of iterations needed to converge the electronic density and the time per time step for MaZe (red) and standard conjugate gradients (blue) are compared for the indicated kinetic energy functionals (G_c is the energy cut-off).
Practical application
The code is intended for condensed matter physicists and for material scientists and it can be used for various purposes related to the subject. Even though some analysis tools are included in the package, the main goal of the software is to produce particles trajectories to be analysed in post-production by means of external software.
MaZe implements the orbital-free formulation of density functional theory, in which the optimisation of the energy functional is performed directly in terms of the electronic density without use of Kohn-Sham orbitals. This feature avoids the need for satisfying the orthonormality constraint among orbitals and allows the computational complexity of the code to scale linearly with the dimensionality of the system. The accuracy of the simulation relies on the choice of the kinetic energy functional, which has to be provided in terms of the electronic density alone.
Documentation and source code
The complete documentation is at this location. The source code is available from the E-CAM Gitlab under the MaZe project (software is under embargo until publication leveraging the developments is achieved. Contact code developers or info@e-cam2020.eu for more information.)
References
[1] Sara Bonella, Alessandro Coretti, Rodolphe Vuilleumier, Giovanni Ciccotti, “Adiabatic motion and statistical mechanics via mass-zero constrained dynamics”, Phys. Chem. Chem. Phys.2020, 22, 10775-10785 DOI: 10.1039/D0CP00163E Pre-print version (open access): https://arxiv.org/abs/2001.03556
Scalability of parallel applications depends on a number of characteristics, among which is efficient communication, equal distribution of work or efficient data lay-out. Especially for methods based on domain decomposition, as it is standard for, e.g., molecular dynamics, dissipative particle dynamics or particle-in-cell methods, unequal load is to be expected for cases where particles are not distributed homogeneously, different costs of interaction calculations are present or heterogeneous architectures are invoked, to name a few. For these scenarios the code has to decide how to redistribute the work among processes according to a work sharing protocol or to dynamically adjust computational domains, to balance the workload. The A Load Balancing Library (ALL) developed within E-CAM at the Julich Supercomputing Center aims to provide an easy and portable way to include dynamic domain-based load balancing into particle based simulation codes. It provides several schemes to find the ideal split of the workload, from the simplest orthogonal non staggered domain decomposition, to the more fancy Voronoi mesh scheme. Within this text we provide an overview of ALL, its capabilities and current use cases, as well as where to find additional information on the library.
Most modern parallelized (classical) particle simulation programs are based on a spatial decomposition method as an underlying parallel algorithm: different processors administrate different spatial regions of the simulation domain and keep track of those particles that are located in their respective region. Processors exchange information
in order to compute interactions between particles located on different processors
to exchange particles that have moved to a region administered by a different processor.
This implies that the workload of a given processor is very much determined by its number of particles, or, more precisely, by the number of interactions that are to be evaluated within its spatial region.
Certain systems of high physical and practical interest (e.g. condensing fluids) dynamically develop into a state where the distribution of particles becomes spatially inhomogeneous. Unless special care is being taken, this results in a substantially inhomogeneous distribution of the processors’ workload. Since the work usually has to be synchronized between the processors, the runtime is determined by the slowest processor (i.e. the one with the highest workload). In the extreme case, this means that a large fraction of the processors are idle during these waiting times. This problem becomes particularly severe if one aims at strong scaling, where the number of processors is increased at constant problem size: Every processor administrates smaller and smaller regions and therefore inhomogeneities will become more and more pronounced. This will eventually saturate the scalability of a given problem, already at a processor number that is still so small that communication overhead remains negligible.
The solution to this problem is the inclusion of dynamic load balancing techniques. These methods redistribute the workload among the processors, by lowering the load of the most busy cores and enhancing the load of the most idle ones. Fortunately, several successful techniques are known already to put this strategy into practice. Nevertheless, dynamic load balancing that is both efficient and widely applicable implies highly non-trivial coding work. Therefore it has not yet been implemented in a number of important codes.
The A Load-Balancing Library (ALL) developed within E-CAM at the Simulation Laboratory Molecular Systems of the Juelich Supercomputing Centre, aims to provide an easy and portable way to include dynamic domain-based load balancing into particle based simulation codes. It was created in the context of an Extended Software Development Workshop (ESDW) within E-CAM (see ALL ESDW event details), where code developers of CECAM community codes were invited together with E-CAM postdocs, to work on the implementation of load balancing strategies. The goal of this activity is to increase the scalability of applications to a larger number of cores on HPC systems, for spatially inhomogeneous systems, and thus to reduce the time-to-solution of the applications .
Particle system before and after the load balancing. Left: equal domain sizes with bad balance; right: unequal domain sizes and good work load.
ALL includes several load-balancing schemes, with additional approaches currently being added. The following list gives an overview about the currently included schemes:
Tensor-Product method: For the Tensor-Product method, the work on all processes (subdomains) is reduced over the cartesian planes in the systems. This work is then equalized by adjusting the borders of the cartesian planes.
Staggered Grid Method: For the staggered-grid scheme, a 3-step hierarchical approach is applied: work over the Cartesian planes is reduced before the borders of these planes are adjusted; in each of the Cartesian planes the work is reduced for each Cartesian column, these columns are then adjusted to each other to homogenise the work in each column; the work between neighbouring domains in each column is adjusted. Each adjustment is done locally with the neighbouring planes, columns or domains by adjusting the adjacent boundaries.
Unstructured Mesh Method: In contrast to the Tensor-Product method and the Staggered Grid Method, the unstructured mesh method adjusts domains not by moving boundaries but vertices, i.e. corner points, of domains. For each vertex, a force, based on the differences in work of the neighboring domains, is computed and the vertex is shifted in a way to equalize the work between these neighboring domains.
Voronoi Mesh Method: Similar to the topological mesh method (Unstructured Mesh Method), the Voronoi mesh method computes a force, based on work differences. In contrast to the topological mesh method, the force acts on a Voronoi point rather than a vertex, i.e. a point defining a Voronoi cell, which describes the domain. Consequently, the number of neighbors is not a conserved quantity, i.e. the topology may change over time.
Histogram-based Staggered Grid Method: The histogram-based staggered-grid scheme results in the same grid as the staggered-grid scheme (see Staggered Grid Method), this scheme uses the cumulative work function in each of the three cartesian directions in order to generate this grid. Using histograms and the previously defined distribution of process domains in a cartesian grid, this scheme generates in three steps a staggered-grid result, in which the work is distributed as evenly as the resolution of the underlying histogram allows. In contrast to the other schemes this scheme depends on a global exchange of work between processes.
Use cases
ALL is being tested with the HemeLB code[1] from the Centre of Excellence CompBiomed. A recent paper describes how HemeLB’s developments in memory management and load balancing (with ALL) allow near linear scaling performance of the code on hundreds of thousands of computer codes[2].
ALL is implemented in the multi-GPU version of DL_MESO_DPD package (see related news item here). The intention of this integration is to allow for better performance when modelling complex systems with DL_MESO_DPD[3], like large proteins or lipid bilayers, redistributing the work load across the GPUs.
References
[1] D. Groen, J. Hetherington, H.B. Carver, R.W. Nash, M.O. Bernabeu, and P.V. Coveney. Analysing and modelling the performance of the HemeLB lattice-Boltzmann simulation environment. Journal of Computational Science, 4(5):412 – 422, 2013. doi: https://doi.org/10.1016/j.jocs.2013.03.002. // HemeLB URL: www.hemelb.org
[2] McCullough JWS et al. 2021 Towards blood flow in the virtual human: efficient self-coupling of HemeLB. Interface Focus 11: 20190119. doi: http://dx.doi.org/10.1098/rsfs.2019.0119
Abstract: We present coupled electron-ion Monte Carlo results for the principal Hugoniot of deuterium together with an accurate study of the initial reference state of shock-wave experiments. We discuss the influence of nuclear quantum effects, thermal electronic excitations, and the convergence of the potential energy surface by wave-function optimization within variational Monte Carlo and projection quantum Monte Carlo methods. Compared to a previous study, our calculations also include low pressure-temperature (P,T) conditions resulting in close agreement with experimental data, while our revised results at higher (P,T) conditions still predict a more compressible Hugoniot than experimentally observed.
During the making-of of the E-CAM Comics the collaboration with the founders and directors of the Comics&Science magazine, Roberto Natalini and Andrea Plazzi, and with the authors of the comics, Giovanni Eccher (writer) and Sergio Ponchione (cartoonist), was remarkable.
In this conversation about how “it all came to be”, Sara Bonella (CECAM Deputy Director), Ignacio Pagonabarraga (CECAM Director) and the Comics&Science team will shed light on how they found a way to explain laypeople about modelling, simulation and HPC through comics.
Short biography of the people involved in this conversation
GIOVANNI ECCHER: Is a comics writer and a scriptwriter for movies and animation. He also directed the documentary “Magnus – Il segno del Viandante”. He wrote the story of EKHAM The Wise.
SERGIO PONCHIONE: Is one of the artists of the multi-awarded series Mercurio Loi. Among his books: Obliquomo, Memorabilia and Grotesque. He is the cartoonist behind EKHAM The Wise.
ROBERTO NATALINI: Is the Director of the CNR Institute for applied mathematics “Mauro Picone” (Cnr-Iac), in Rome. He is the director and editor-in-chief of Comics&Science, together with Andrea Plazzi.
ANDREA PLAZZI: Is an author and editor with a scientific background and active in the field of comics. He is the director and editor-in-chief of Comics&Science, together with Roberto Natalini.
SARA BONELLA: Is the Deputy Director of CECAM and E-CAM’s work-package leader. She is also Maître de d’Enseignement et de Recherche at EPF-Lausanne.
IGNACIO PAGONABARRAGA: Is the Director of CECAM and E-CAM’s technical manager. He is a Professor at the University of Barcelona.
In a newly successful PRACE-ICEI proposal, E-CAM, FocusCoE, HPC Carpentry and EESSI join forces to bring HPC resources to the classroom in a simple, secure and scalable way. Our plan is to reproduce the model developed by the Canadian open-source software project Magic Castle. The proposed solution creates virtual HPC infrastructure(s) in a public cloud, in this case on the Fenix Research Infrastructure, and generates temporary event-specific HPC clusters for training purposes, including a complete scientific software stack. The scientific software stack is fully optimised for the available hardware and will be provided by the European Environment for Scientific Software Installations (EESSI).
Description
EU-wide requirements for HPC training are exploding as the adoption of HPC in the wider scientific community gathers pace. However, the number of topics that can be thoroughly addressed without providing access to actual HPC resources is very limited, even at the introductory level. In cases where such access is available, security concerns and the overhead of the process of provisioning accounts make the scalability of this approach questionable.
EU-wide access to HPC resources on the scale required to meet the training needs of all countries is an objective that we attempt to address with this project. The proposed solution essentially provisions virtual HPC system(s) in a public cloud, in this case on the Fenix Research Infrastructure. The infrastructure will dynamically create temporary event-specific HPC clusters for training purposes, including a scientific software stack. The scientific software stack will be provided by the European Environment for Scientific Software Installations (EESSI) which uses a software distribution system developed at CERN, CernVM-FS, and makes a research-grade scalable software stack available for a wide set of HPC systems, as well as servers, desktops and laptops (including MacOS and Windows!).
The concept is built upon the solution of Compute Canada, Magic Castle, which aims to recreate the Compute Canada user experience in public clouds (there is even a presentation where the main developer creates a cluster just by talking to his phone!). Magic Castle uses the open-source software Terraform and HashiCorp Language (HCL) to define the virtual machines, volumes, and networks that are required to replicate a virtual HPC infrastructure.
In addition to providing a dynamically provisioned HPC resource, the project will also offer a scientific software stack provided by EESSI. This model is also based on a Compute Canada approach and enables replication of the EESSI software environment outside of any directly related physical infrastructure.
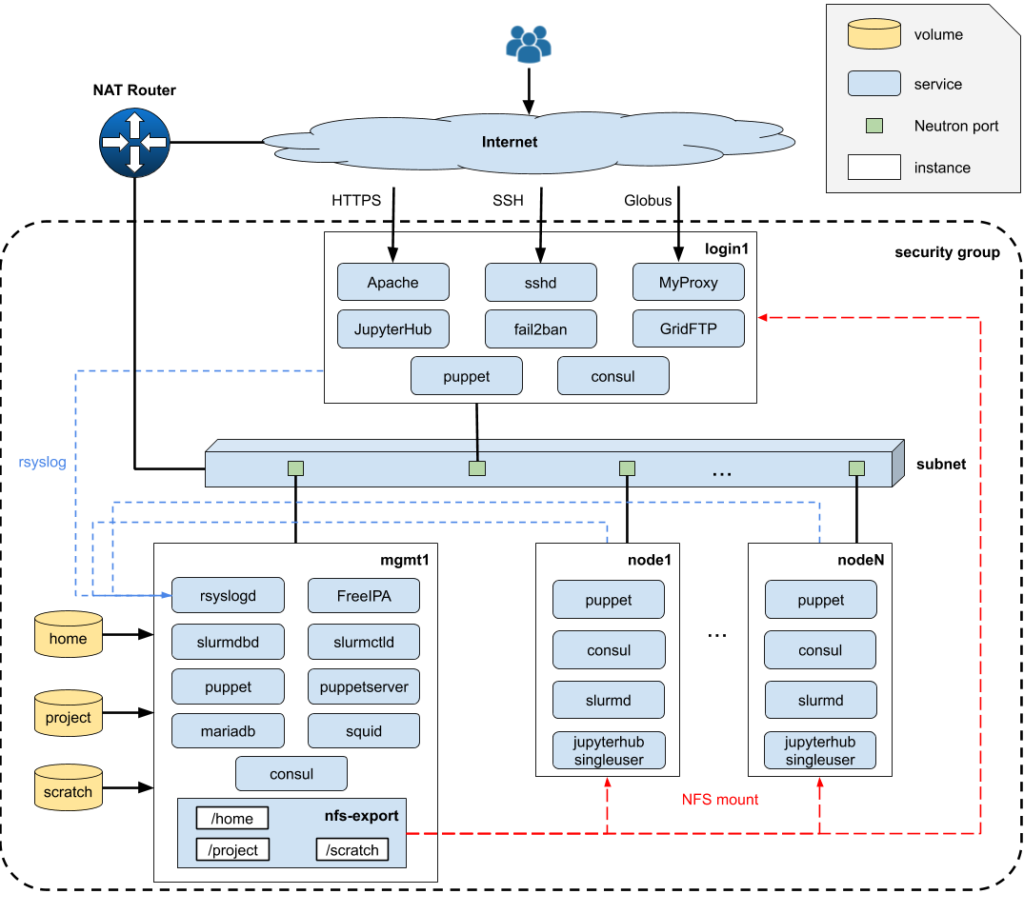
Our adaption of Magic Castle aims to recreate the EESSI HPC user experience, for training purposes, on the Fenix Research Infrastructure. After deployment, the user is provided with a complete HPC cluster software environment including a Slurm scheduler, a Globus Endpoint, JupyterHub, LDAP, DNS, and a wide selection of research software applications compiled by experts with EasyBuild.
With the resources made available to the project, we plan to run 6 HPC training events from January to July 2021. These training events are connected to the Centres of Excellence E-CAM and FocusCoE and with HPC Carpentry.
Few software, like DL_MESO, userMESO and LAMMPS, can currently simulate large Dissipative Particle Dynamics (DPD) simulations. In particular, DL_MESO [1, 2] has recently been ported to multi-GPU architectures and runs efficiently up to 4096 GPUs, an effort supported by E-CAM.
In this E-CAM Extended Software Development Workshop, the developers of the DL_MESO code themselves will provide an introduction to DPD, DL_MESO, its features and functionalities, as well as they will initiate participants to parallel programming of hybrid CPU-GPU systems. Part of the workshop will be dedicated to theory lectures and hands-on sessions on GPU architectures and OpenACC (NVidia DLI course) given by an NVidia DLI Certified Instructor, followed by the practical case of porting DL_MESO to OpenACC.
Interested in participating? Join us on the 18-22 January for this ONLINE course. Express your motivation to attend the workshop directly through the CECAM website at https://www.cecam.org/workshop-details/8
[2] M. A. Seaton, R. L. Anderson, S.Metz, and W. Smith, “DL_MESO: highly scalable mesoscale simulations,”Molecular Simulation, vol. 39, no. 10, pp. 796–821, Sep. 2013