The transformation of a beautiful idea born via simulation into a commercial opportunity is recognised as a disruptive technology. At the heart of this ongoing story is advanced simulation using massively parallel computation, rare-event methods and genetic engineering.
Proof of concept : recognition as a disruptive technology
Author: Donal Makernan, University College Dublin, Ireland
Last week I received an email asking if I would be willing to accept the ‘2021 NovaUCD Licence of the Year Award’ for the licence of the disruptive molecular switch platform technology to a US based company with an initial application as a point-of-care medical diagnostic for COVID-19 and influenza. Of course I said yes, and since then received a beautiful statue of a metal helix mounted on a black marble plinth via courier (displayed on the right). It is nice that our work gets this sort of recognition given all of the effort it has taken to get to this point. In my last blog post I wrote of the first steps towards commercialization of our technology. Since then, everything has intensified. The company funding this research collaboration with University College Dublin has now over 20 people in the USA dedicated to its commercialization – including old hands hired from well known immuno-diagnostic and pharmaceutical companies, medical doctors, engineers and sales-persons. On our side, our team has grown and now includes two software-engineers/simulators trained in part through E-CAM while they were studying theoretical physics, and four molecular biologists. In addition, contract research and manufacturing organizations are also now being engaged so as to be ready for clinical testing and scale-up when we have fully optimized our diagnostic sensors for COVID 19. Hard to believe it is only one year since we met the key commercial people. We continue to simulate various forms of the sensor so as to optimize its performance and commercialization, and for that HPC resources from PRACE partners from Ireland (ICHEC), Switzerland (CSCS) and Italy (Cineca) have been of huge help. We also are dedicating a lot of effort in software development so as to speed up our ability to estimate free energy properties such as binding affinities, which turn out to be much tricker than one might expect when proteins are very large, such as between antibodies and target antigens such as the COVID 19 spike protein. That methodology and software arose from an E-CAM pilot project – and would appear to have a potential utility way beyond our first expectations. The E-CAM Centre of Excellence grant from the EU will be finished soon (31st March). Hopefully it will emerge soon again.
Scalability of parallel applications depends on a number of characteristics, among which is efficient communication, equal distribution of work or efficient data lay-out. Especially for methods based on domain decomposition, as it is standard for, e.g., molecular dynamics, dissipative particle dynamics or particle-in-cell methods, unequal load is to be expected for cases where particles are not distributed homogeneously, different costs of interaction calculations are present or heterogeneous architectures are invoked, to name a few. For these scenarios the code has to decide how to redistribute the work among processes according to a work sharing protocol or to dynamically adjust computational domains, to balance the workload. The A Load Balancing Library (ALL) developed within E-CAM at the Julich Supercomputing Center aims to provide an easy and portable way to include dynamic domain-based load balancing into particle based simulation codes. It provides several schemes to find the ideal split of the workload, from the simplest orthogonal non staggered domain decomposition, to the more fancy Voronoi mesh scheme. Within this text we provide an overview of ALL, its capabilities and current use cases, as well as where to find additional information on the library.
Most modern parallelized (classical) particle simulation programs are based on a spatial decomposition method as an underlying parallel algorithm: different processors administrate different spatial regions of the simulation domain and keep track of those particles that are located in their respective region. Processors exchange information
in order to compute interactions between particles located on different processors
to exchange particles that have moved to a region administered by a different processor.
This implies that the workload of a given processor is very much determined by its number of particles, or, more precisely, by the number of interactions that are to be evaluated within its spatial region.
Certain systems of high physical and practical interest (e.g. condensing fluids) dynamically develop into a state where the distribution of particles becomes spatially inhomogeneous. Unless special care is being taken, this results in a substantially inhomogeneous distribution of the processors’ workload. Since the work usually has to be synchronized between the processors, the runtime is determined by the slowest processor (i.e. the one with the highest workload). In the extreme case, this means that a large fraction of the processors are idle during these waiting times. This problem becomes particularly severe if one aims at strong scaling, where the number of processors is increased at constant problem size: Every processor administrates smaller and smaller regions and therefore inhomogeneities will become more and more pronounced. This will eventually saturate the scalability of a given problem, already at a processor number that is still so small that communication overhead remains negligible.
The solution to this problem is the inclusion of dynamic load balancing techniques. These methods redistribute the workload among the processors, by lowering the load of the most busy cores and enhancing the load of the most idle ones. Fortunately, several successful techniques are known already to put this strategy into practice. Nevertheless, dynamic load balancing that is both efficient and widely applicable implies highly non-trivial coding work. Therefore it has not yet been implemented in a number of important codes.
The A Load-Balancing Library (ALL) developed within E-CAM at the Simulation Laboratory Molecular Systems of the Juelich Supercomputing Centre, aims to provide an easy and portable way to include dynamic domain-based load balancing into particle based simulation codes. It was created in the context of an Extended Software Development Workshop (ESDW) within E-CAM (see ALL ESDW event details), where code developers of CECAM community codes were invited together with E-CAM postdocs, to work on the implementation of load balancing strategies. The goal of this activity is to increase the scalability of applications to a larger number of cores on HPC systems, for spatially inhomogeneous systems, and thus to reduce the time-to-solution of the applications .
Particle system before and after the load balancing. Left: equal domain sizes with bad balance; right: unequal domain sizes and good work load.
ALL includes several load-balancing schemes, with additional approaches currently being added. The following list gives an overview about the currently included schemes:
Tensor-Product method: For the Tensor-Product method, the work on all processes (subdomains) is reduced over the cartesian planes in the systems. This work is then equalized by adjusting the borders of the cartesian planes.
Staggered Grid Method: For the staggered-grid scheme, a 3-step hierarchical approach is applied: work over the Cartesian planes is reduced before the borders of these planes are adjusted; in each of the Cartesian planes the work is reduced for each Cartesian column, these columns are then adjusted to each other to homogenise the work in each column; the work between neighbouring domains in each column is adjusted. Each adjustment is done locally with the neighbouring planes, columns or domains by adjusting the adjacent boundaries.
Unstructured Mesh Method: In contrast to the Tensor-Product method and the Staggered Grid Method, the unstructured mesh method adjusts domains not by moving boundaries but vertices, i.e. corner points, of domains. For each vertex, a force, based on the differences in work of the neighboring domains, is computed and the vertex is shifted in a way to equalize the work between these neighboring domains.
Voronoi Mesh Method: Similar to the topological mesh method (Unstructured Mesh Method), the Voronoi mesh method computes a force, based on work differences. In contrast to the topological mesh method, the force acts on a Voronoi point rather than a vertex, i.e. a point defining a Voronoi cell, which describes the domain. Consequently, the number of neighbors is not a conserved quantity, i.e. the topology may change over time.
Histogram-based Staggered Grid Method: The histogram-based staggered-grid scheme results in the same grid as the staggered-grid scheme (see Staggered Grid Method), this scheme uses the cumulative work function in each of the three cartesian directions in order to generate this grid. Using histograms and the previously defined distribution of process domains in a cartesian grid, this scheme generates in three steps a staggered-grid result, in which the work is distributed as evenly as the resolution of the underlying histogram allows. In contrast to the other schemes this scheme depends on a global exchange of work between processes.
Use cases
ALL is being tested with the HemeLB code[1] from the Centre of Excellence CompBiomed. A recent paper describes how HemeLB’s developments in memory management and load balancing (with ALL) allow near linear scaling performance of the code on hundreds of thousands of computer codes[2].
ALL is implemented in the multi-GPU version of DL_MESO_DPD package (see related news item here). The intention of this integration is to allow for better performance when modelling complex systems with DL_MESO_DPD[3], like large proteins or lipid bilayers, redistributing the work load across the GPUs.
References
[1] D. Groen, J. Hetherington, H.B. Carver, R.W. Nash, M.O. Bernabeu, and P.V. Coveney. Analysing and modelling the performance of the HemeLB lattice-Boltzmann simulation environment. Journal of Computational Science, 4(5):412 – 422, 2013. doi: https://doi.org/10.1016/j.jocs.2013.03.002. // HemeLB URL: www.hemelb.org
[2] McCullough JWS et al. 2021 Towards blood flow in the virtual human: efficient self-coupling of HemeLB. Interface Focus 11: 20190119. doi: http://dx.doi.org/10.1098/rsfs.2019.0119
In a newly successful PRACE-ICEI proposal, E-CAM, FocusCoE, HPC Carpentry and EESSI join forces to bring HPC resources to the classroom in a simple, secure and scalable way. Our plan is to reproduce the model developed by the Canadian open-source software project Magic Castle. The proposed solution creates virtual HPC infrastructure(s) in a public cloud, in this case on the Fenix Research Infrastructure, and generates temporary event-specific HPC clusters for training purposes, including a complete scientific software stack. The scientific software stack is fully optimised for the available hardware and will be provided by the European Environment for Scientific Software Installations (EESSI).
Description
EU-wide requirements for HPC training are exploding as the adoption of HPC in the wider scientific community gathers pace. However, the number of topics that can be thoroughly addressed without providing access to actual HPC resources is very limited, even at the introductory level. In cases where such access is available, security concerns and the overhead of the process of provisioning accounts make the scalability of this approach questionable.
EU-wide access to HPC resources on the scale required to meet the training needs of all countries is an objective that we attempt to address with this project. The proposed solution essentially provisions virtual HPC system(s) in a public cloud, in this case on the Fenix Research Infrastructure. The infrastructure will dynamically create temporary event-specific HPC clusters for training purposes, including a scientific software stack. The scientific software stack will be provided by the European Environment for Scientific Software Installations (EESSI) which uses a software distribution system developed at CERN, CernVM-FS, and makes a research-grade scalable software stack available for a wide set of HPC systems, as well as servers, desktops and laptops (including MacOS and Windows!).
The concept is built upon the solution of Compute Canada, Magic Castle, which aims to recreate the Compute Canada user experience in public clouds (there is even a presentation where the main developer creates a cluster just by talking to his phone!). Magic Castle uses the open-source software Terraform and HashiCorp Language (HCL) to define the virtual machines, volumes, and networks that are required to replicate a virtual HPC infrastructure.
In addition to providing a dynamically provisioned HPC resource, the project will also offer a scientific software stack provided by EESSI. This model is also based on a Compute Canada approach and enables replication of the EESSI software environment outside of any directly related physical infrastructure.
Our adaption of Magic Castle aims to recreate the EESSI HPC user experience, for training purposes, on the Fenix Research Infrastructure. After deployment, the user is provided with a complete HPC cluster software environment including a Slurm scheduler, a Globus Endpoint, JupyterHub, LDAP, DNS, and a wide selection of research software applications compiled by experts with EasyBuild.
With the resources made available to the project, we plan to run 6 HPC training events from January to July 2021. These training events are connected to the Centres of Excellence E-CAM and FocusCoE and with HPC Carpentry.
The E-CAM issue of Comics & Science has just been released on-line…and it’s just the beginning of the adventure!
Identifying exciting and original tools to engage the general public with advanced research is an intriguing and non-trivial challenge for the scientific community. E-CAM decided to try something unusual, and embarked on an interesting and slightly bizarre experience: collaborating with experts and artists to use comics to talk about HPC and simulation and modelling!
The adventure started when CECAM Deputy Director and E-CAM Work-Package leader Sara Bonella visited the CNR Institute for applied mathematics “Mauro Picone” (Cnr-Iac), in Rome, and became acquainted with the work of Comics&Science, a magazine published by CNR Edizioni to promote the relationship between science and entertainment. The magazine was created in 2013 by Roberto Natalini, Director of the Cnr-Iac, and Andrea Plazzi, author and editor with a scientific background and active in the field of comics.
Adopting the unique language of the comics, Comics&Science communicates science in a funny and understandable way via original stories that are always edited by some of the best authors and cartoonists in town. For the E-CAM issue, we had the good fortune to collaborate with Giovanni Eccher, comics writer and scriptwriter for movies and animations, and Sergio Ponchione, illustrator and cartoonist.
Giovanni and Sergio created for us the unique story of Ekham the wise, a magnificent witch that – with an accurate model and the help of a High Performance Cauldron (!) – enables Prince Variant to defeat the fearful Dragon that has kidnapped Princess Beauty. As usual, the King had promised the Princess’s hand to the vanquisher of the dragon, but things don’t turn out exactly as expected…
In addition to the comics, the E-CAM issue of Comics&Science presents several articles describing – in a language targeted at young adults, and, in general, lay public – what are simulations in advanced research and the role of High Performance Computing. The issue also contains a statement from the European Commission on its vision for HPC. We are very grateful to our authors, that include Ignacio Pagonabarraga, Catarina Mendonça, Sara Bonella, Christoph Dellago, and Gerhard Sutmann, for playing with us.
The issue has been produced in partnership with CECAM, coordinator of E-CAM, and the longest standing institution promoting fundamental research on advanced computational methods.
The E-CAM issue of Comics&Science is freely available on our website at https://www.e-cam2020.eu/e-cam-issue-of-comics-science/. Should you wish to use this new toy to promote modelling and simulation, get in touch at info@e-cam2020.eu and let us know about your plans: we are happy to share the material provided that provenance is acknowledged.
The “first outing” of the E-CAM issue of Comics&Science took place on Friday 30 October at 14:15 CET with a presentation (in Italian) in the on-line programme of the 2020 Lucca Comics&Games Festival. A recording of that moment is available at https://www.youtube.com/watch?v=BUysRG0zlCk.
An article about E-CAM has just been released with the Autumn edition of the EU Research Magazine. The EU research magazine is Europe’s leader in research dissemination.
The piece consists on an interview to Prof. Ignacio Pagonabarraga, E-CAM technical manager, Dr. Sara Bonella, leader of our work-package focused on quantum dynamics and also of the work-package that deals with the interactions with industry; Dr. Donal Mackernan, leader of our dissemination work-package and Dr. Jony Castagna, programmer in E-CAM.
The interview describes E-CAM’s work in
(1) developing software targeted at the needs of both academic and industrial end-users, with applications from drug development to the design of new materials ;
(2) tuning those codes to run on HPC machines, through application co-design and the provision of HPC oriented libraries and services;
(3) training scientists from industry and academia ; and
(4) supporting industrial end-users in their use of simulation and modelling, via workshops and direct discussions with experts in the CECAM community.
Traditionally high-throughput computing (HTC) workloads are looked down upon in the HPC space, however the scientific use case for extreme-scale resources required by coordinated HTC workflows exists. For such cases where there may be thousands of tasks each requiring peta-scale computing, E-CAM has extended the data-analytics framework Dask with a capable and efficient library to handle such workloads.
Introduction
The initial motivation for E-CAM’s High Throughput Library, jobqueue_features library [1], is driven by the ensemble-type calculations that are required in many scientific fields, and in particular in the materials science domain. A concrete example is the study of molecular dynamics with atomistic detail, where timesteps must be used on the order of a femto-second. Many problems in biological chemistry and materials science involve events that only spontaneously occur after a millisecond or longer (for example, biomolecular conformational changes). That means that around 1012 time steps would be needed to see a single millisecond-scale event. This is the problem of “rare events” in theoretical and computational chemistry.
Modern supercomputers are beginning to make it possible to obtain trajectories long enough to observe some of these processes, but to fully characterize a transition with proper statistics, many examples are needed. In such cases the same peta-scale application must be run many thousands of times with varying inputs. For this use case, we were conceptually attracted to the Dask philosophy [2]: Dask is a specification that encodes task schedules with minimal incidental complexity using terms common to all Python projects, namely dicts, tuples, and callables.
However, Dask or it’s extensions do not currently support task-level parallelization (in particular multi-node tasks). We have been able to leverage the Dask extension dask_jobqueue [3] and build upon it’s functionality to include support for MPI-enabled task workloads on HPC systems. The resulting approach, described in the rest of this piece, allows for multi-level parallelization (at the task level via MPI, and at the framework level via Dask) while leveraging all of the pre-existing effort within the Dask framework such as scheduling, resilience, data management and resource scaling.
E-CAM’s HTC library was created in collaboration with a PRACE team in Wrocław, and is the subject of an associated white paper [4]. This effort is under continuous improvement and development. A series of dedicated webinars will happen in the fall of 2020, which will be an opportunity for people to learn how to use Dask and dask_jobqueue (to submit Dask workloads on a resource scheduler like SLURM), and to implement our library jobqueue_features in their codes. Announcement and more information will soon be available at https://www.e-cam2020.eu/calendar/.
Methodology
The jobqueue features library [1] is an extension of dask_jobqueue [3] which in turn utilizes the Dask [2] data analytics framework. dask_jobqueue is targeted at deploying Dask on several job queuing systems, such as SLURM or PBS with the use of a Python programming interface. The main enhancements of basic dask_jobqueue functionality is heavily extending the configuration implementation to handle MPI runtimes and different resource specifications. This allows the end-user to conveniently create parallelized tasks without extensive knowledge of the implementation details (e.g., the resource manager or MPI runtime). The library is primarily accessed through a set of Python decorators: on_cluster, task and mpi_task. The on_cluster decorator gets or creates clusters, which in turn submit worker resource allocation requests to the scheduler to execute tasks. The mpi_task decorator derives from task and enhances it with MPI specific settings (e.g. the MPI runtime and related settings).
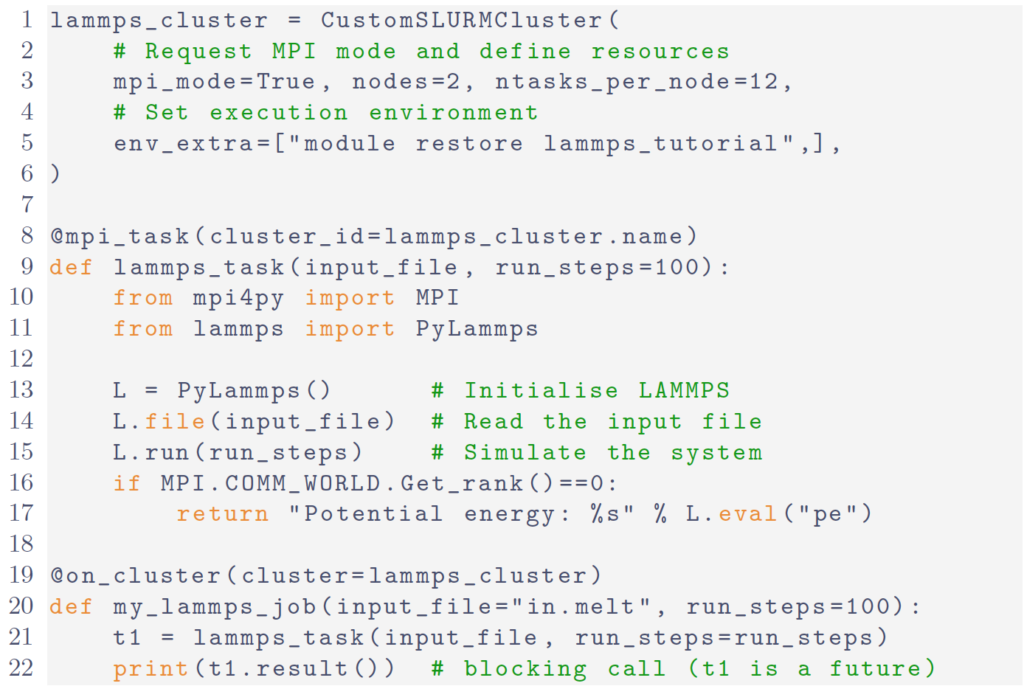
Fig. 1: Example of decorator usage to parallelize computation
In Fig. 1 we show a minimal, but complete, example which uses the mpi_task and on_cluster decorators for a LAMMPS execution. The configuration, communication and serialization is isolated and hidden from user code.
Any call to my_lammps_job results in the lammps_task function being executed remotely by a lammps_cluster worker allocated by the resource manager with 2 nodes and 12 MPI tasks per node. The code can be executed interactively in a Jupyter notebook. To overlap calculations one would need to return the t1 future rather than the actual result.
Findings
The library can effectively handle simultaneous workloads on GPU, KNL and CPU partitions of the JURECA supercomputer [5]. The caveat with respect to the hardware environment is that you need to be able to have a network that supports TCP (usually via IPoIB) or UCX connections between the scheduler and the workers (which process and execute the tasks that are queued).
With respect to the software stack, this is an issue highlighted by the KNL booster of JURECA. On the booster, there is a different micro-architecture and it is required to completely change your software stack to support this. The design of the software stack implementation on JURECA simplifies this but ensuring your tasks are run in the correct software environment is one of the more difficult things to get right in the library. As a result, the configuration of the clusters (which define the template required to submit workers to the appropriate queue of the resource manager) can be quite non-trivial. However, they can be located within a single file which will need to be tuned for the available resources. With respect to the tasks themselves, no tuning is necessarily required.
We see ∼90% throughput efficiency for trivial tasks, if the tasks executed for any reasonable length of time this throughout efficiency would be much higher.
Conclusions
The library is flexible, scalable, efficient and adaptive. It is capable of simultaneously utilising CPUs, KNL and GPUs (or any other hardware) and dynamically adjusting its use of these resources based on the resource requirements of the scheduled task workload. The ultimate scalability and hardware capabilities of the solution is dictated by the characteristics of the tasks themselves with respect to these. For example, for the use case described here these would mean the hardware and scalability capabilities of LAMMMPS with a further multiplicative factor coming from the library for the number of tasks running simultaneously. There is, unsurprisingly, room for further improvement and development, in particular related to error handling and limitations related to the Python GIL.
[4] A. O. Cais, D. Swenson, M. Uchronski and A. Wlodarczyk. (2019, Augoust 14). “Task Scheduling Library for Optimising Time-Scale Molecular Dynamics Simulations,” Zenodo. http://doi.org/10.5281/zenodo.3527643
Dr. Jony Castagna, Science and Technology Facilities Council, United Kingdom
Abstract
Jony Castagna recounts his transition from industry scientist to research software developer at the STFC, his E-CAM rewrite of DL_MESO allowing the simulation of billion atom systems on thousands of GPGPUs, and his latest role as Nvidia ambassador focused on machine learning.
The power of advanced simulation combined with statistical theory , experimental know-how and high performance computing is used to design a protein based molecular switch sensor with remarkable sensitivity and significant industry potential. The sensor technology has applications across commercial markets including diagnostics, immuno-chemistry, and therapeutics.
In the last few years, modelling of rare events has made tremendous progress and several computational methods have been put forward to study these events. Despite this effort, new approaches have not yet been included, with adequate efficiency and scalability, in common simulation packages. One objective of the Classical Dynamics Work Package of the project E-CAM is to close this gap. The present text is an easy-to-read article on the use of path sampling methods to study rare events, and the role of the OpenPathSampling package to performing these simulations. Practical applications of rare events sampling and scalabilities opportunities in OpenPathSampling are also discussed.