The E-CAM issue of Comics & Science has just been released on-line…and it’s just the beginning of the adventure!
Identifying exciting and original tools to engage the general public with advanced research is an intriguing and non-trivial challenge for the scientific community. E-CAM decided to try something unusual, and embarked on an interesting and slightly bizarre experience: collaborating with experts and artists to use comics to talk about HPC and simulation and modelling!
The adventure started when CECAM Deputy Director and E-CAM Work-Package leader Sara Bonella visited the CNR Institute for applied mathematics “Mauro Picone” (Cnr-Iac), in Rome, and became acquainted with the work of Comics&Science, a magazine published by CNR Edizioni to promote the relationship between science and entertainment. The magazine was created in 2013 by Roberto Natalini, Director of the Cnr-Iac, and Andrea Plazzi, author and editor with a scientific background and active in the field of comics.
Adopting the unique language of the comics, Comics&Science communicates science in a funny and understandable way via original stories that are always edited by some of the best authors and cartoonists in town. For the E-CAM issue, we had the good fortune to collaborate with Giovanni Eccher, comics writer and scriptwriter for movies and animations, and Sergio Ponchione, illustrator and cartoonist.
Giovanni and Sergio created for us the unique story of Ekham the wise, a magnificent witch that – with an accurate model and the help of a High Performance Cauldron (!) – enables Prince Variant to defeat the fearful Dragon that has kidnapped Princess Beauty. As usual, the King had promised the Princess’s hand to the vanquisher of the dragon, but things don’t turn out exactly as expected…
In addition to the comics, the E-CAM issue of Comics&Science presents several articles describing – in a language targeted at young adults, and, in general, lay public – what are simulations in advanced research and the role of High Performance Computing. The issue also contains a statement from the European Commission on its vision for HPC. We are very grateful to our authors, that include Ignacio Pagonabarraga, Catarina Mendonça, Sara Bonella, Christoph Dellago, and Gerhard Sutmann, for playing with us.
The issue has been produced in partnership with CECAM, coordinator of E-CAM, and the longest standing institution promoting fundamental research on advanced computational methods.
The E-CAM issue of Comics&Science is freely available on our website at https://www.e-cam2020.eu/e-cam-issue-of-comics-science/. Should you wish to use this new toy to promote modelling and simulation, get in touch at info@e-cam2020.eu and let us know about your plans: we are happy to share the material provided that provenance is acknowledged.
The “first outing” of the E-CAM issue of Comics&Science took place on Friday 30 October at 14:15 CET with a presentation (in Italian) in the on-line programme of the 2020 Lucca Comics&Games Festival. A recording of that moment is available at https://www.youtube.com/watch?v=BUysRG0zlCk.
E-CAM started in October 2015 and received funding from the European Union’s Horizon 2020 R&I program for a period of 66-months.
Built around the scientific community of the Centre Européen de Calcul Atomique et Moléculaire (CECAM), E-CAM was coordinated by CECAM Headquarters (HQ) at EPFL, and was a partnership of 14 CECAM Nodes, 4 PRACE centres and one Centre for Industrial Computing (Hartree Centre).
The present final report provides an overview of the project results during the EU funding period, and includes:
project highlights
overview of the project results in each Work-Package (WP)
Computation based methods play a growing role in all stages of accelerated medicine pipelines responding to industry challenges of drug substance development.
Abstract
APC was created In 2011 by Dr. Mark Barrett and Prof. Brian Glennon of the University College Dublin School of Chemical and Bioprocess Engineering with a mission to harness state of the art research methods & know-how to accelerate drug process development. Since then it has grown organically partnering with companies across the world, large and small, to bring medicines to market at unprecedented speed. Computation-based methods play a growing role in all stages of its medicine pipeline as explained by Dr. Jacek Zeglinski in this E-CAM interview on the challenges to Industry of drug substance development.
What is APC?
APC, the company I work for stands for Applied Process Company, and we are based in South County Dublin in Ireland, actually, just half an hour walk from the Irish Sea. APC is a global company, although it’s perhaps not very big, it is an impactful company because we collaborate with a range of big pharma companies across the world, both big and small. We provide services to them to help accelerate the development of active pharmaceutical ingredients (APIs), both small molecules, and biomolecules. We work in a number of domains of product development, starting from early-stage development through to optimization up to scale up and technology transfer.
Can you tell us how you got involved with APC?
I learned about APC in 2012, while working as a postdoc at the University of Limerick. At that time APC was a newly established start up company. Some time later two friends from my research group joined APC, so very soon I had first-hand opinion of the company. It appeared that the superior company culture and the dive-deep research focus were sufficiently strong arguments for me to join APC in early 2019.
What challenges does APC focus on, say in the context of drug development?
When we refer to drugs or drug substances, we have in mind the powder forms that are the basis for making tablets. Usually, they are crystalline but sometimes they are in amorphous form. There are a number of challenges we face. The poor solubility of active ingredients is probably the most important. Until recently people would have considered APIs to be small molecules, but nowadays they are getting larger and larger, up to 1000 grams per mole in molecular weight. They are also quite flexible and complex and that actually brings challenges related to their solubility. Most of the APIs we are handling have poor solubility in a range of solvents. That would translate to insufficient bio-availability, and make it difficult to manufacture those APIs with high productivity (i.e. producing low yield and throughput) if we could not solve the problem of solubility.
The second challenge we face is polymorphism. Crystalline materials can exist in a number of different crystal forms, those forms are interrelated in terms of stability, some of them are metastable and the most stable ones and not always easy to obtain. Sometimes one gets unwanted solvates or hydrates at the start of the development process when screening is being done in a range of different solvents. The third issue relates to particle size and shape, which can cause poor processability, filter-ability, flow-ability, compressibility, and difficulty to form tablets. Particles that are too large can have poor or inconsistent dissolution rates and bioavailability. Agglomeration is another challenge, and consequent difficulties to remove impurities, particularly when they are hidden in the voids within agglomerates.
What computational approaches do you use?
In our work in optimizing processes, we mainly do a lot of experiments but we also use computational methods. I will briefly highlight the latter, starting with our typical workflow for solvent selection for crystallization processing.
Solubility Predictions for Crystallisation Processes
Computational tools allow us to screen many more solvents than would be possible using experimentation alone. The workflow usually starts with 70 solvents, which are screened computationally regarding their solubility temperature dependence, the propensity of forming solvates or hydrates, and their utility for impurity purging, ending up with less than 10 promising solvents for experimental validation. This computational screening which is done in two to three days would take several weeks or even months were experiment used instead. We then check for the crystal form, for purity, and some other parameters that allow us to narrow down our candidates to two, three, or even one solvent for small-scale crystallisation experiments. The most optimum solvent system is further used to develop the full process followed by a final scale-up demonstration. So as you can see that computational part is a very important piece of this workflow and it really aids the solvent selection process. Regarding software, we are using mainly two platforms from Biovia, one is COSMO-therm (combined with a DFT-based program – TURBOMOLE) and the other one is Materials Studio. With COSMO we predict solubilities, and also the propensity for solvate/cocrystal and even salt formation. With Materials Studio, we search for the low energy conformations of molecules and use those conformations for solubility prediction using COSMO, so the two software codes work together. With Materials Studio, we also do lattice and cohesive energy calculations, so as to estimate thermodynamic stability of polymorphs, or find imperfections in the crystal lattice or predict the shape of crystals. We are constantly developing these capabilities and trying to do more predictive modeling. Looking at the molecular complexity of the future medicines we handle, we clearly see that there is a real need to better understand the solid-state features of those APIs, which very often are multicomponent materials, e.g. cocrystals, salt-cocrystal-hydrate hybrids etc.
How do the computational solubility predictions compare with experiment?
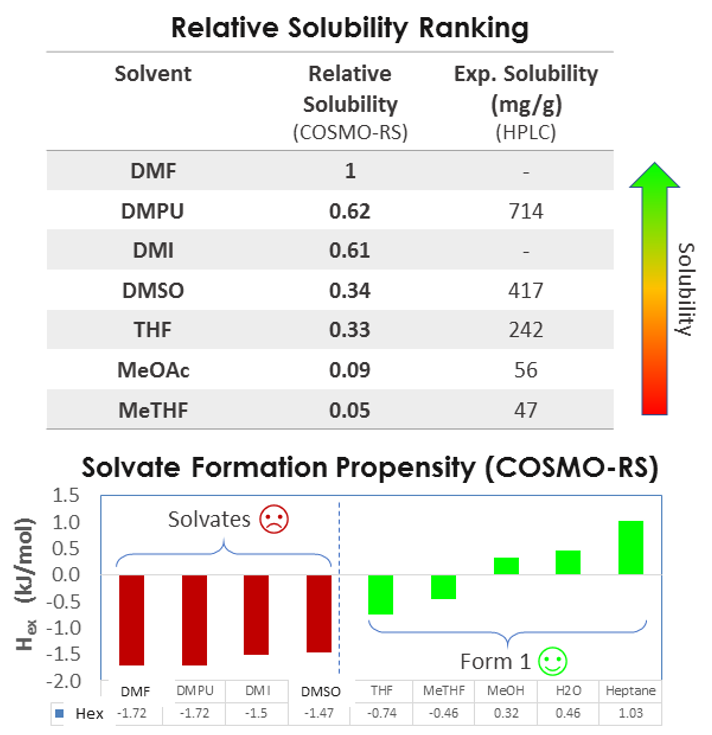
I would like to show how relative solubility predictions performed with COSMO compare with experiments for a medium-sized API molecule (500g/Mol) in a variety of solvents. As you can see there’s a good match between the rank order of solubility.
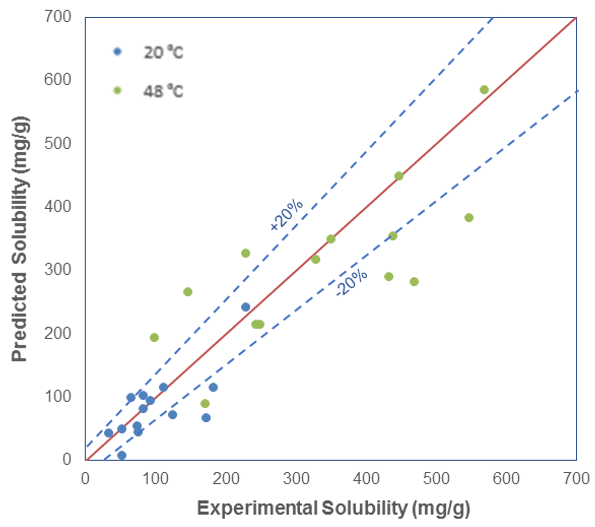
So we can predict relative solubility and, in addition, we can compute the propensity for solvate formation, that is the enthalpy of mixing, which is related to the interaction between solvent and solute. More negative values indicate exothermic events and stronger interactions, and more positive values indicate endothermic events and unfavorable mixing. So the case study presented was a very successful validation of this approach. In addition to relative solubility, we can predict absolute solubility and compare it with experiment, for example at two different temperatures, 20 and 48 °C.
As you can see, for some of the systems, the solubility is predicted very well, but for most systems, the computational and experimental results are within 20% of each other. At lower temperatures, the agreement is very good, but at higher temperatures, we see the predictions are not as accurate.
In addition to single solvents, we can predict solubility in solvent mixtures. This is a very useful application because, for many APIs, there is no single neat solvent that can be identified. In such cases, there is often a solvent mixture that can be identified which gives rise to good solubility for the API. For example, in the binary solvent mixture of water and ethyl acetate, certain solvent ratios give rise to good solubility for a variety of solutes. We can also have ternary, quaternary, and higher mixtures of solvents studied computationally.
How important is the stability of different conformers of an API in a solvent?
Conformational Aspects in Solubility Predictions
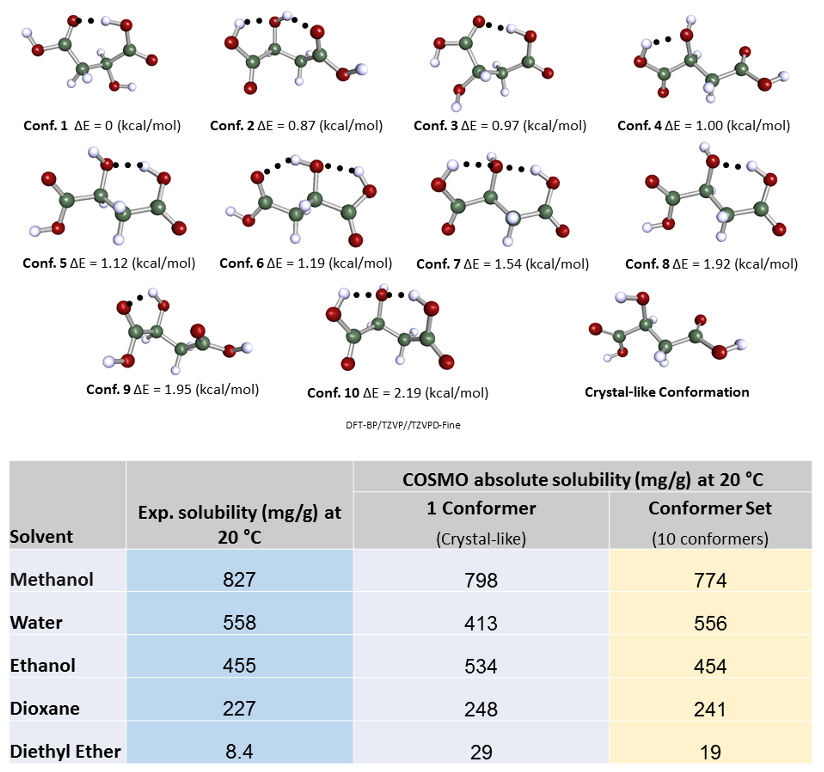
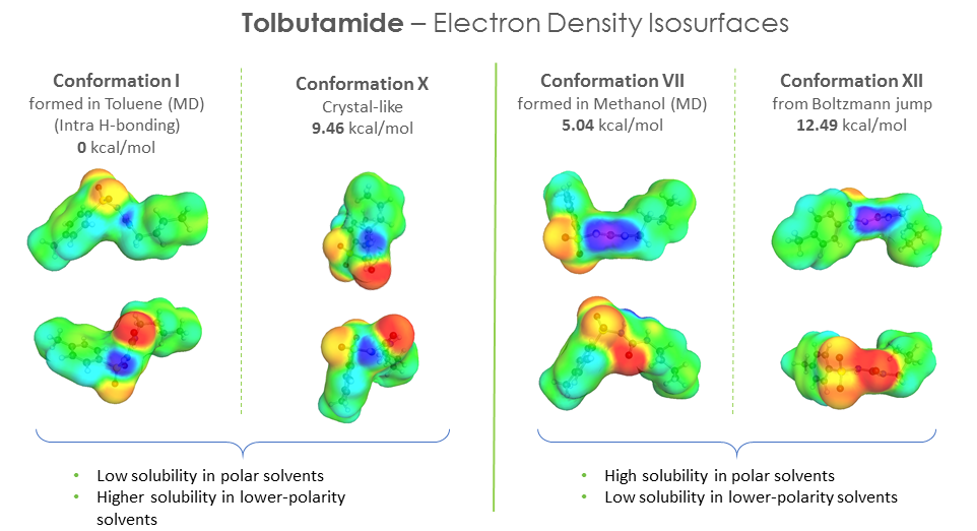
This is perhaps more fundamental, and interesting. I will show an example of solubility predictions for malic acid, and focus on different conformations. Malic acid can make a number of intra-molecular hydrogen bonds and that will be reflected in different relative conformational energies. There’s a hypothesis that regarding solubility predictions, the lowest energy conformations should be dominant because this is the confirmation that should be the most probable and most frequently occurring in solution. However, we find that this is not always the case. We can compare the predicted values of solubilities for five different solvents with experimental values for the crystal-like molecular conformation obtained in vacuum with DFT using COSMO and ten other low energy conformers identified based on their relative energetic stability.
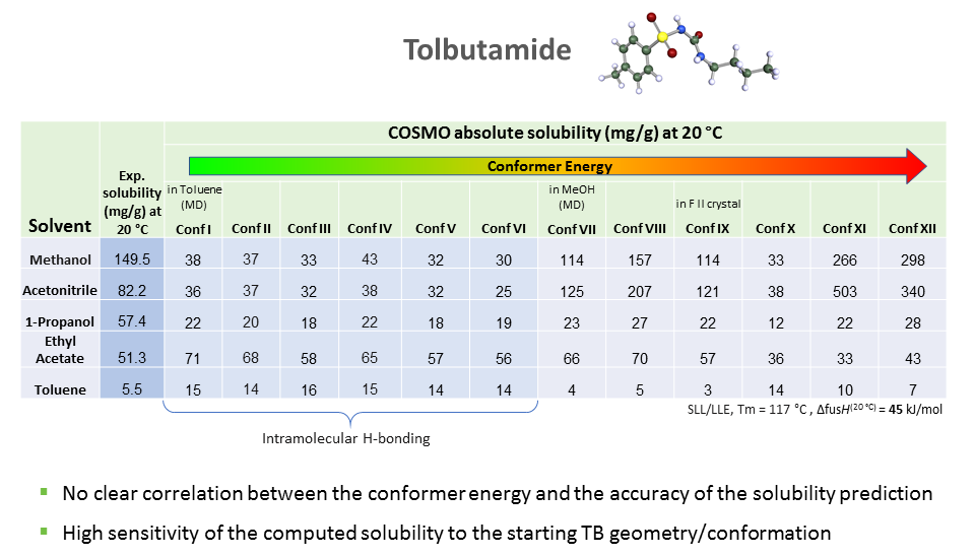
As we can see the predicted solubility compare fairly well with experiment, particularly in terms of relative ranking of solubility, as this allows the best solvent to be chosen. We see that the comparison using ten conformers is slightly better for predicting absolute solubility. However, it is not always the case that we have such good agreement for solubilities between prediction and experiment. For molecules that are larger and more flexible, the challenge increases. Another case we have studied is tolbutamide. In polar solvents such as methanol, the molecule should not have an intra-molecular hydrogen bond conformation, but in non-polar or low polarity solvents such as toluene, it should. We generated a variety of conformations some of which had intra-molecular hydrogen bonds and predicted the solubilities using those different conformations having different relative energies.
The hypothesis that the lower the energy of the conformer, the better its solubility does not apply in this case. There is no clear correlation between conformer energy and the accuracy of the solubility predicted when compared with the experiment for tolbutamide.
We also looked at the electron density iso-surfaces for the different conformers and found a correlation between the polar “domains” in the distribution (local concentration of positive and negative charge distributions) and the solubility in polar solvents and vice-versa for non-polar solvents – where the distribution of positive and negative charges were more scattered and less pronounced. It would be nice to quantify this and explore it further.
How do you predict the morphology of APIs and how well do they compare with experiments?
Crystal Shape/Morphology Prediction of Pharmaceutical Compounds
In our projects, before starting any experiments we try to predict as many properties as possible, including shape/morphology of crystals of a particular API. The predictions are made in vacuum, and very often reflect the experimental morphology. There are some exceptions, but in most cases, we find good agreement. We use an attachment energy theory which assumes that crystal growth is proportional to the attachment energy, i.e. the energy released when a slice of crystal is added to a particular facet (or lattice direction). The higher the attachment energy on the facet, the faster the growth in that direction. Based on that, we can predict the shape of the crystalline particle and the intrinsic propensity for its growth in particular directions, which will also give us the theoretical aspect ratio. It turns out that this is often related to the relative polarity of different facets; basically the number of polar atoms at different surfaces. Usually, the higher the polarity, the stronger the hydrogen bonding, and the faster will be the growth rate in that direction. However, there can be exceptions to that. For example, for molecules that are elongated and somewhat flat like Clofazimine, there are no intermolecular hydrogen bonds that occur, and molecular packing is more important. Ideally, we would like to predict the effect of the solvent on the crystal shape. Sometimes we are able to find a correlation between the surface chemistry and the morphology we are trying to predict and the impact of a particular solvent type. For example, some systems have high polarity charge distributions on certain facets, and in such cases, if we use polar-protic solvents, they would preferentially interact with polar atoms on that facet and inhibit crystal growth there. On the other hand, they could allow growth along low polarity directions. We found some experimental preliminary evidence of this, but it still has to be confirmed. We are trying to use this sort of analysis to predict which solvent will generate the desired morphology. We also explore more complex modelling approaches, including implicit and explicit solvent effects on crystal morphology and our modelling work done in this context is promising. I would like to thank the CEO of APC, Dr. Mark Barret for the opportunity to do this work, and my co-authors, Dr. Marko Ukrainczyk and Prof. Brian Glennon.
The E-CAM HPC Centre of Excellence and a PRACE team in Wroclaw have teamed up to develop High Throughput Computing (HTC) based tools to enable the computational investigation of reaction mechanisms in complex systems. These tools might help us gain understanding of enzymatic mechanisms used by the SARS-CoV-2 main protease [1]
Studying reaction mechanisms in complex systems requires powerful simulations. Committor analysis is a powerful, but computationally expensive tool, developed for this purpose. An alternative, less expensive option, consists in using the committor to generate initial trajectories for transition path sampling. In this project, the main goal was to integrate the committor analysis methodology with an existing software application, OpenPathSampling [2,3] (OPS), that performs many variants of transition path sampling (TPS) and transition interface sampling (TIS), as well as other useful calculations for rare events. OPS is performance portable across a range of HPC hardware and hosting sites..
The Committor analysis is essentially an ensemble calculation that maps straightforwardly to an HTC workflow, where typical individual tasks have moderate scalability and indefinite duration. Since this workflow requires dynamic and resilient scalability within the HTC framework, OPS was coupled to E-CAM’s HTC library jobqueue_features[4] that leverages the Dask [5, 6] data analytics framework and implements support for the management of MPI-aware tasks.
The HTC library jobqueue_features proved to be resilient and to scale extremely well, meaning it can handle a very high number of simultaneous tasks: a stress test showed it can scale out to 1M tasks on all available architectures. OPS was expanded and its integration with the jobqueue features library was made trivial. In its current state, OPS can now almost seamlessly transition from use on a personal laptop to some of the largest HPC sites in Europe.
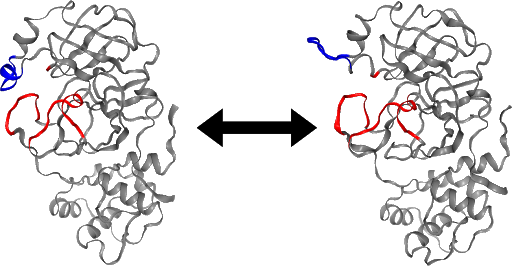
Integrating OPS and the HTC library resulted in an unprecedented parallelised committor simulation capability. These tools are currently being implemented for a committor simulation of the SARS-CoV-2 main protease. An initial analysis of the stable states, based on a long trajectory provided by D.E. Shaw Research [7] suggests that a loop region of the protein may act as a gate to the active site (Figure). This conformational change may regulate the accessibility of the active site of the main protease, and a better understanding of its mechanism could aid drug design.
The committor simulation can be used to explore the configuration space (taking more initial configurations), or to improve the accuracy of the calculated committor value (running more trajectories per configuration). Altogether, such data will provide insight into the dynamics of the protease loop region and the mechanism of its gate-like activity. In addition, the trajectories generated by the committor simulation can also be used as initial conditions for further studies using the transition path sampling approach.
Left image: “closed” configuration. Right Image: “open” configuration.
References
[1] Milosz Bialczak, Alan O’Cais, Mariusz Uchronski, & Adam Wlodarczyk. (2020). Intelligent HTC for Committor Analysis. http://doi.org/10.5281/zenodo.4382017
[2] David W.H. Swenson, Jan-Hendrik Prinz, Frank Noé, John D. Chodera, and Peter G. Bolhuis. “OpenPathSampling: A flexible, open framework for path sampling simulations. 1. Basics.” J. Chem. Theory Comput. 15, 813 (2019). https://doi.org/10.1021/acs.jctc.8b00626
[3] David W.H. Swenson, Jan-Hendrik Prinz, Frank Noé, John D. Chodera, and Peter G. Bolhuis. “OpenPathSampling: A flexible, open framework for path sampling simulations. 2. Building and Customizing Path Ensembles and Sample Schemes.” J. Chem. Theory Comput. 15, 837 (2019). https://doi.org/10.1021/acs.jctc.8b00627
[4] Alan O’Cais, David Swenson, Mariusz Uchronski, and Adam Wlodarczyk. Task Scheduling Library for Optimising Time-Scale Molecular Dynamics Simulations, August 2019.
[5] Dask Development Team. Dask: Library for dynamic task scheduling, 2016.
[6] Matthew Rocklin. Dask: Parallel computation with blocked algorithms and task scheduling. In Kathryn Hu and James Bergstra, editors, Proceedings of the 14th Python in Science Conference, pages 130 – 136, 2015.[7] No specific author. Long trajectory provided by D.E. Shaw Research. https://www.deshawresearch.com/downloads/download_trajectory_sarscov2.cgi/, 2020. [Online; accessed 22-Oct-2020].
The transformation of a beautiful idea born via simulation into a commercial opportunity is recognised as a disruptive technology. At the heart of this ongoing story is advanced simulation using massively parallel computation, rare-event methods and genetic engineering.
Proof of concept : recognition as a disruptive technology
Author: Donal Makernan, University College Dublin, Ireland
Last week I received an email asking if I would be willing to accept the ‘2021 NovaUCD Licence of the Year Award’ for the licence of the disruptive molecular switch platform technology to a US based company with an initial application as a point-of-care medical diagnostic for COVID-19 and influenza. Of course I said yes, and since then received a beautiful statue of a metal helix mounted on a black marble plinth via courier (displayed on the right). It is nice that our work gets this sort of recognition given all of the effort it has taken to get to this point. In my last blog post I wrote of the first steps towards commercialization of our technology. Since then, everything has intensified. The company funding this research collaboration with University College Dublin has now over 20 people in the USA dedicated to its commercialization – including old hands hired from well known immuno-diagnostic and pharmaceutical companies, medical doctors, engineers and sales-persons. On our side, our team has grown and now includes two software-engineers/simulators trained in part through E-CAM while they were studying theoretical physics, and four molecular biologists. In addition, contract research and manufacturing organizations are also now being engaged so as to be ready for clinical testing and scale-up when we have fully optimized our diagnostic sensors for COVID 19. Hard to believe it is only one year since we met the key commercial people. We continue to simulate various forms of the sensor so as to optimize its performance and commercialization, and for that HPC resources from PRACE partners from Ireland (ICHEC), Switzerland (CSCS) and Italy (Cineca) have been of huge help. We also are dedicating a lot of effort in software development so as to speed up our ability to estimate free energy properties such as binding affinities, which turn out to be much tricker than one might expect when proteins are very large, such as between antibodies and target antigens such as the COVID 19 spike protein. That methodology and software arose from an E-CAM pilot project – and would appear to have a potential utility way beyond our first expectations. The E-CAM Centre of Excellence grant from the EU will be finished soon (31st March). Hopefully it will emerge soon again.
The development of enhanced sampling methods to investigate rare but important events has always been a focal point in the molecular simulation field. Such methods often rely on prior knowledge of the reaction coordinate. However, the search for this reaction coordinate is at the heart of the rare event problem. Transition path sampling (TPS) circumvents this problem by generating an ensemble of dynamical trajectories undergoing the activated event. The reaction coordinate is extracted from the resulting path ensemble using variants of machine learning, making it an output of the method instead of an input. Over the last 20 years, since its inception, many extensions of TPS have been developed. Perhaps surprisingly, large‐scale TPS simulations on complex molecular systems have become possible only recently. Other important developments include the transition interface sampling (TIS) methodology to compute rate constants, the application to multiple states, and adaptive path sampling. The development of OpenPathSampling and PyRETIS has enabled easy and flexible use and implementation of these and other novel path sampling algorithms. In this progress report, a brief overview of recent developments, novel algorithms, and software is given. In addition, several application areas are discussed, and a future outlook for the next decade is given.
This module sets up the European Environment for Scientific Software Installations (EESSI) for use in GitHub Workflows.
The European Environment for Scientific Software Installations (EESSI) is a collaboration between a number of academic and industrial partners in the HPC community to set up a shared stack of scientific software installations to avoid the installation and execution of sub-optimal applications on HPC resources. The software stack is intended to work on laptops, personal workstations, HPC clusters and in the cloud, which means the project will need to support different CPUs, networks, GPUs, and so on.
The EESSI project is supported by E-CAM, and forms the basis of the software stack used within the LearnHPC project (which is also supported by E-CAM).
EESSI can be leveraged in continuous integration (CI) workflows to easily provide the dependencies of an application. With this module we create a GitHub Action for EESSI so that it can be used within a projects CI on GitHub. By using the Action, you can use environment modules to resolve the dependencies of your application in highly predictable and reproducible way. This includes state-of-the-art compilers, MPI runtimes and mathematical libraries.
This work relates to the implementation of a performance portable version of DL_MESO (DPD) using the Kokkos library. It focuses on porting to DL_MESO (DPD) the first and second loops of the Verlet Velocity (VV) scheme for the time marching scheme. This allows to run DL_MESO on NVidia GPUs as well as on other GPUs or architectures (many-core hardware like KNL), allowing performance portability as well as separation of concern between computational science and HPC.
Description
The VV scheme is made of 3 steps:
a first velocity and particle positions integration by Delta t/2,
a force calculation, and
a second velocity integration by Delta t/2.
Steps 1) and 2) are documented is the following two modules
Note: Kokkos is a C++ library, while DL_MESO (DPD) is in Fortran90 Language. The current implementation requires a transfer between Fortran to C++, due to the use of Fortran pointers not bound using the ISO_C_BINDING standard. This constraint will be removed in future versions of DL_MESO.
Practical application
With the advent of heterogeneous hardware, achieving performance portability across different architectures is one of the main challenges in HPC. In fact, while specific languages, like CUDA, can give best performance for the NVidia hardware, they cannot be used with different GPU vendors limiting the usage across supercomputers worldwide.
In this module we use Kokkos, developed at Sandia National Laboratories, which consist of several C++ templated libraries which provide the capability to offload a workload to several different architectures, taking care of the memory layout and transfer between host and device.
Documentation and source code
The modules documentation is available on our software repository here. The modules have also been pushed into DL_MESO git repository as explained in the modules documentation.
This module improves the connection of n2p2to HPC software, in particular to LAMMPS, by creating a pull request to the official LAMMPS repository. Furthermore, the build process for the n2p2 interface library is enhanced to allow for a selective activation of different interfaces. A first application is also supported: the user contribution of an n2p2 interface to CabanaMD which uses Kokkos to drive MD simulations with NNP support on GPUs.
Description
This module is based on n2p2 (NeuralNetworkPotentialPackage), a C++ code for generation and application of neural network potentials used in molecular dynamics simulations. The source code and documentation are located here:
Although n2p2 was already shipped with source files for patching LAMMPS before (see here) , the build process required manual intervention of users. To avoid this in future versions of LAMMPS a pull request was created to include the n2p2/LAMMPS interface by default as a user package. In order to conform with LAMMPS contribution guidelines multiple issues were resolved, triggering these changes/additions to LAMMPS and n2p2:
• Modify the CMake build process to search and include n2p2
• Create additional documentation about the build settings
• Create a suitable example which can be shipped with LAMMPS
• Adapt documentation of the LAMMPS “pair_style nnp” command
• Change n2p2 to conformwith LAMMPS “bigbig” settings
• Change the source files “pair_nnp.(cpp/h)” to conform with the LAMMPS coding style
Furthermore, the n2p2 build system was adapted to allow for multiple interfaces to other software packages, with an option to select only those of interest to the user. As a first application, the user contributed CabanaMD interface was integrated in the new build process. CabanaMD is an ECP proxy application which makes use of the Kokkos performance portability library and n2p2 to port neural network potentials in MD simulations to GPUs and other HPC hardware.
Practical applications
The integration of neural network potentials directly in LAMMPS via a user package with linkage to n2p2 will greatly enhance the visibility and user experience. User will also be able to retrieve information about the neural network potential method and its use directly on the LAMMPS documentation page. Modifying the n2p2 build process to allow for multiple interfacing software simplifies the development of CabanaMD. This contribution of n2p2 users can be viewed as a precursor of a Kokkos implementation of NNPs in LAMMPS. Ultimately, such an addition to n2p2/LAMMPS would be of great value for the community as it would allow for running molecular dynamics simulation with NNPs on GPUs.
In this conversation with Andreas Singraber, post-doc in E-CAM until last month, we will discover the ensemble of his work to expand the Neural Network Potential (NNP) Package n2p2 and to improve user accessibility to the code via the LAMMPS package. Andreas will talk about new tools that he developed during his E-CAM pilot project, that can provide valuable input for future developments of NNP based coarse-grained models. He will describe how E-CAM has impacted his career and led him to recently integrate a software company as a scientific software engineer.
With Dr. Andreas Singraber, Vienna Ab initio Simulation Package (VASP)